With over 48,500 mailboxes now running successfully on Exchange 2010 it’s tempting to think of the migration as ‘done’. But appearances can be deceiving: at the beginning of last week I was stuck with twelve mailboxes remaining – none of which would migrate. Because I’ve been using the ‘SuspendWhenReadyToComplete‘ switch it allows the job to get to the autosuspended stage successfully. That gives an illusion of success – but any attempt to actually complete the migration of these mailboxes failed, at the final hurdle, with a MAPI error.
Initially there didn’t seem to be a great deal of obvious help when reviewing the migration logs either. The logs reported zero corrupt items so the usual fix (deleting the problem messages) couldn’t apply. What you do see is a failure type listed as:
MapiExceptionInvalidParameter
This is elaborated a little as:
Error: MapiExceptionInvalidParameter: Unable to modify table. (hr=0x80070057, ec=-2147024809)
Sadly it transpires that this is far from an unusual reason for a move to fail – there are literally dozens of posts and queries about it on the search engines – and the calibre of the options you’re presented with to fix it vary wildly depending on which sites feature most prominently in your preferred engine’s results.
Let’s take a look at what’s recommended.
- Rules and Out-Of-Office
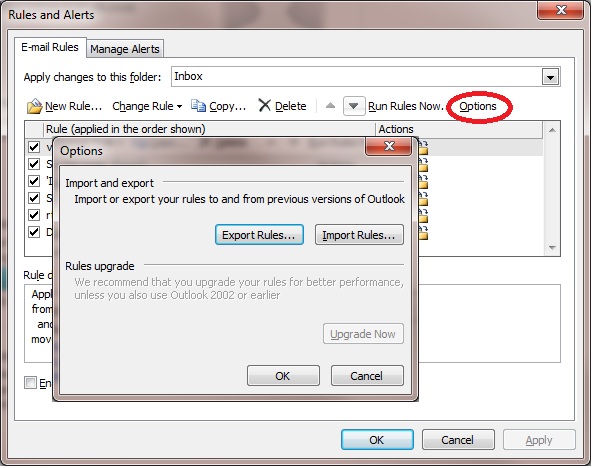
The standard recommendations usually start with a suggestion that the user searches for (and removes) their rules from the mailbox, also checking for broken Out-Of-Office messages (which are often overlooked although they’re also a kind of rule). To add insult to injury hardly anyone ever seems to mention that Outlook has the facility to export those rules beforehand. I’d be pretty cheesed off it all of my carefully-crafted rules were callously wiped out without that simple prior precaution: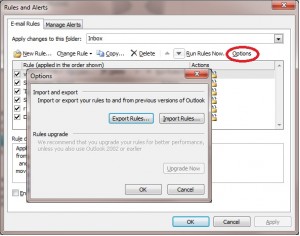 So what’s the next step? Once you’ve got that backup of those rules (!) conventional advice is to launch Outlook with the /CLEANRULES switch to make sure that you really are rid of them. But that’s not terribly helpful if that user’s only email client is on Linux.
So what’s the next step? Once you’ve got that backup of those rules (!) conventional advice is to launch Outlook with the /CLEANRULES switch to make sure that you really are rid of them. But that’s not terribly helpful if that user’s only email client is on Linux.
- MFCMAPI
Many sites recommend delving into the mailbox using a tool such as MFCMAPI. Our strict rules about user mailbox privacy seemed pretty certain to preclude me from going down that route except as a last resort.
- Export-Mailbox
This Powershell cmdlet is the server-side equivalent to an Outlook export but it has a far lower tolerance to MAPI errors. It was unlikely to work here and, even after approval to try it for one user had been obtained, it bombed out with MAPI errors, as expected.
The most viable remaining option for me – to avoid any accusation of privacy-violation – seemed to be to reattempt the move invoking the -IgnoreRuleLimitErrors switch but, again, that was running the risk of jeopardising user content. I’m sure it’s all a lot easier in an organisation with managed desktops rather than our ISP-style service! Disappointingly it seemed that, in cases like these, there was always going to be some kind of imposed data loss but with a likelihood of not knowing exactly what was being sacrificed.
Instead I returned to the logs looking for inspiration from a couple of these mailboxes that I had managed to migrate. Below is an abridged version of what a failed-with-MAPI-error migration log looks like. The vital clue is right at the end:
18/05/2012 14:10:34 [MBX09] ‘<name>‘ created move request.
18/05/2012 14:10:37 [CAS03] The Microsoft Exchange Mailbox Replication service ‘CAS03.ad.oak.ox.ac.uk’ (14.1.355.1 caps:07) is examining the request.
18/05/2012 14:10:37 [CAS03] Connected to target mailbox ‘Primary’, database ‘db005’, Mailbox server ‘MBX01.ad.oak.ox.ac.uk’ Version 14.1 (Build 218.0).
18/05/2012 14:10:37 [CAS03] Connected to source mailbox ‘Primary’, database ‘EXMBX04\SG03\EXMBX04SG03’, Mailbox server ‘EXMBX04.ad.oak.ox.ac.uk’ Version 8.3 (Build 192.0).
18/05/2012 14:10:37 [CAS03] Request processing started.
18/05/2012 14:10:37 [CAS03] Mailbox signature will not be preserved for mailbox ‘Primary’. Outlook clients will need to restart to access the moved mailbox.
18/05/2012 14:10:37 [CAS03] Source Mailbox information before the move:
Regular Items: 25508, 2.545 GB (2,732,488,589 bytes)
Regular Deleted Items: 670, 55.41 MB (58,104,875 bytes)
FAI Items: 27, 0 B (0 bytes)
FAI Deleted Items: 0, 0 B (0 bytes)
<SNIP>
18/05/2012 14:19:09 [CAS03] Final sync has started.
18/05/2012 14:19:19 [CAS03] Changes reported in source ‘Primary’: 0 changed folders, 0 deleted folders, 1 changed messages.
18/05/2012 14:19:19 [CAS03] Incremental Sync ‘Primary’ completed: 1 changed items.
18/05/2012 14:19:22 [CAS03] Fatal error MapiExceptionInvalidParameter has occurred.
Error details: MapiExceptionInvalidParameter: Unable to modify table. (hr=0x80070057, ec=-2147024809)
Diagnostic context:
<SNIP>
——–
Folder: ‘/Top of Information Store/Deleted Messages’, entryId [len=46, data=<long string of hex>], parentId [len=46, data= <long string of hex> ]
18/05/2012 14:19:22 [CAS03] Relinquishing job.
There’s the problem! A folder called ‘Deleted Messages’ which is found right at the top of the Information Store for eight of the remaining users’ mailboxes. This is beyond a coincidence and strongly suggests to me that this folder has been added by a particular email client. I have my suspicions about which one…
Problem solved!
Sure enough, if the user removes this ‘Deleted Messages’ folder from their mailbox they can then be migrated successfully. It seems that it’s not the messages within it that are the problem – it all seems to be tied in to that particular folder, empty or otherwise. A review of the failed migration logs for the other remaining users found a similar issue for two of them: a folder called ‘Trash’. The similarity of likely purpose suggests that a similar client-based trend could be at work here. Again, I’m hoping that the users will remove these folders and the migration will succeed.
This still leaves us with two unfortunate users who have a different problem with their mailbox migration: the move hangs at the ‘completing’ stage. This is the one point where a user is actually blocked from their mailbox and in Ex2010 it’s rarely noticeable (it should be momentary). But with these two users the ‘completing’ stage keeps on going. Eventually it times out and permits the user back into the mailbox that it’s been blocking. I’ve had to tweak the MSExchangeMailboxReplication.exe.config file again (on a default installation you’ll find it here: C:\Program Files\Microsoft\Exchange Server\V14\Bin) to bring the MaxRetries property down from its default of 60. Without that change these two poor users would effectively be blocked from their email for the best part of a day every time I reattempted their upgrade.
Last Resort
If all else fails it’s likely that you’ll need to bite the bullet and dive into the world of database repair tools. Backups, Outlook exports and taking a copy of the EDB file are all sensible precautions before going any further.
The old favourite, ISINTEG, makes what will probably be its last ever appearance here. I’m unlikely to need it again in the future: it’s been superseded by two Powershell cmdlets (New-MailboxRepairRequest and New-PublicFolderDatabaseRepairRequest) for Exchange 2010. I won’t mourn the loss of ISINTEG much though. The new cmdlets don’t require the database to be dismounted and can be limited in scope to just the one mailbox under examination which represents a huge leap forward. It’ll also be nice not to have to leave Powershell and head over to the command prompt just to get it to work. For old times’ sake, here’s the syntax:
Isinteg –s /<servername> –fix –test alltests
The final step could well be the nuclear option of ESEUTIL. Aside from one relatively harmless switch (/D for defragmentation) all of the likely uses for this tool will lose something from the store. Rather than go there though in this instance I’m able to escalate the issue. So I’m awaiting Microsoft’s recommended solution rather than ploughing on alone. I’ll update this post when they’ve provided some further ideas.
UPDATE 28th May 2012: The Last Three Users
The last three Exchange 2007 mailboxes included the two mailboxes which had the hang-on-commit delay and a third where the corruption was the ‘Deleted Items’ folder itself. After several false starts and dead-ends (including an attempt to remove Deleted Items using MFCMAPI and use of Outlook’s /resetfolders switch) I eventually had to concede that time was against me. It would have been preferable to both understand and solve the issue but to continue diagnosing would potentially leave these users’ mailboxes without backup, due to an imposed end of May deadline for ceasing the Exchange 2007 backup service.
The workaround was to export the mailbox content, rules (and every conceivable account setting) then disable the mailbox and create a brand-new one on an Exchange 2010 server. The settings were then reinstated (so the user could get back to sending and receiving) while the mailbox’s backup was gradually restored, backfilling the mailbox. The orphaned Exchange 2007 mailbox was then connected to a generic created-for-the-purpose user just in case any of the mailbox content hadn’t made it across.