One of the frustrations of modern security is the imposition of more onerous user-verification requirements. The benefits of the University introducing Multifactor Authentication (‘MFA’) are well-proven, but it does add a further step that can be inconvenient. In an effort to make life a little bit easier, and following a debate about this area on our IT Discussion mail-list, I share the following advice.
Using a password manager is an essential step in keeping secure. KeePass is an excellent example of the genre and my personal favourite. The latest version has also added a feature that promises to make life that little bit easier: it can act as your MFA authentication app.
I’m assuming that you already have a KeePass entry for your SSO logon, with an auto-type entry set. If not, here’s the auto-type syntax that I use:
{USERNAME}{TAB}{TAB}{TAB}{TAB}{ENTER}{DELAY 1000}{PASSWORD}{ENTER}
The steps to allow KeePass to also handle your MFA are as follows:
1.Visit https://mysignins.microsoft.com/security-info and, yes, log yourself in.
2. Click ‘add sign-in method’:

3. Choose ‘Authenticator App’ from the list:
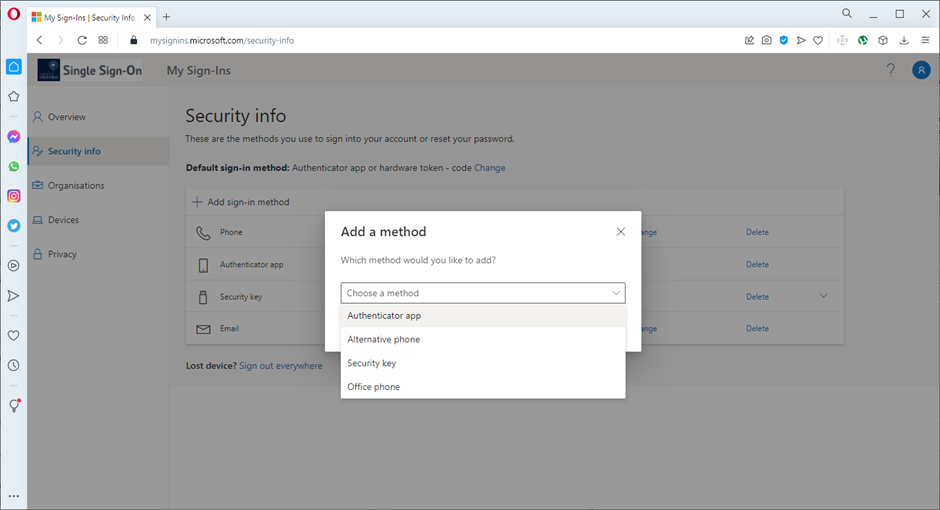
4. Microsoft will recommend their own Authenticator application, but click instead on ‘I want to use a different authenticator app’:
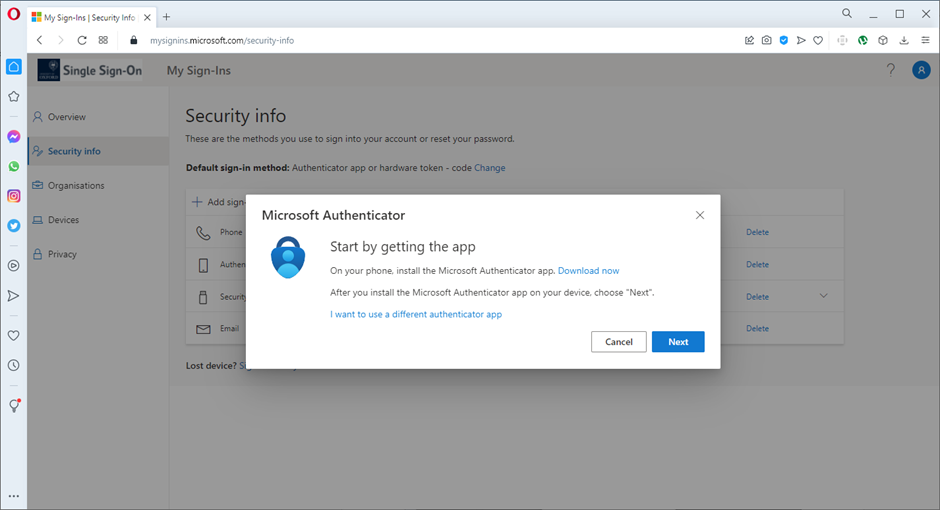
5. You’ll need to have KeePass installed and running shortly, but at this stage you can just click ‘Next’:
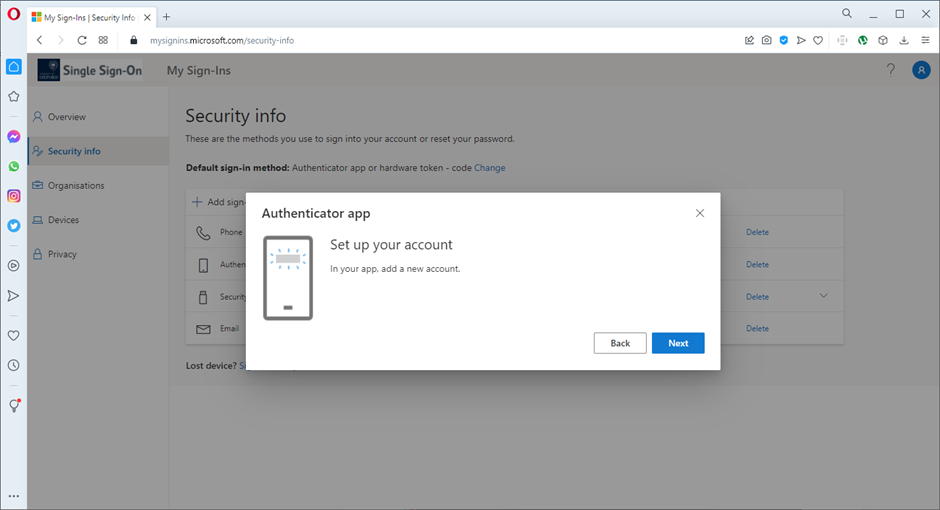
6. You’re presented with a QR code, as most apps are mobile-based and can use a phone camera. Ignore the QR code and click ‘can’t scan image’:

7. The page will create a security key code, with a ‘copy to clipboard’ button next to it. Click on that:

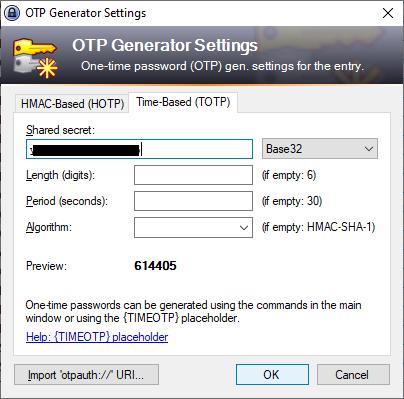
8. Switch to KeyPass, right-click your entry for your University SSO account, select ‘Edit Entry (Quick)’, then ‘OTP Generator settings’. You’ll get a dialogue box. Paste the security code into the ‘shared secret’ field. No other values need to be changed, so then click ‘OK’:
9. When prompted for your MFA authentication code, ask KeyPass to copy that to the clipboard for you:
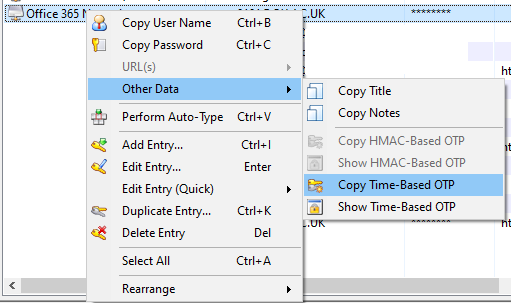
10. In the ‘Enter Code’ window, just right-click and ‘Paste’:
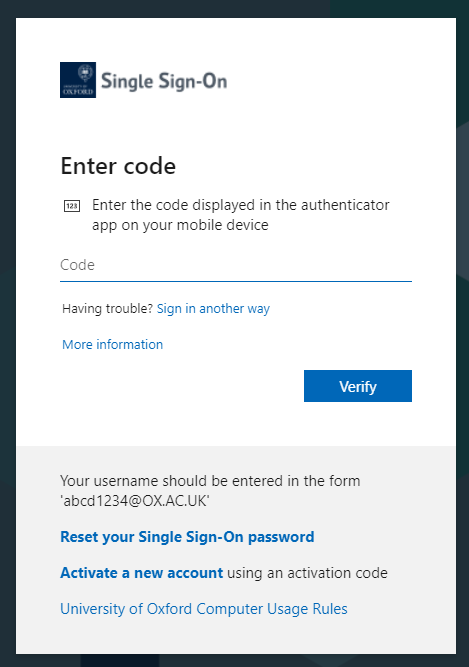
I’m hoping that future revisions of KeePass will make this even easier*, but this is a great step forward and makes a useful app that little bit better still.
EDIT:
The syntax for KeePass to autocomplete your username, password, and MFA code is:
{USERNAME}{TAB}{TAB}{ENTER}{DELAY 2000}{PASSWORD}{ENTER}{DELAY 2000}{TIMEOTP}{ENTER}
FURTHER EDIT, FOLLOWING A REVISION TO THE LOGON DIALOGUE BOX:
The previous autotype string was no longer working, but this reinstates it:
{USERNAME}{TAB}{TAB}{ENTER}{DELAY 2000}{PASSWORD}{TAB}{TAB}{TAB}{ENTER}{DELAY 2000}{TIMEOTP}{ENTER}
