As many of you around the university are likely to be aware of by now, this month we migrated to a new backend infrastructure to support the eduroam service across the city.
This blog post has been written to give an overview of the project, what we set out to achieve and how we got on in general. Needless to say it has been an interesting journey!
For those that may be interested, we intend to write some additional posts later covering some of the more interesting technical aspects in some depth. I will be covering those related to the networking side, whilst my colleague Christopher will be covering those related to the Linux server side.
So what was wrong with the previous infrastructure?
The previous infrastructure was based upon an older generation of Cisco networking hardware (2x Catalyst 3560G switches), a dedicated NetEnforcer appliance performing symmetric bandwidth rate-limiting per client device and a pair of Linux servers performing NAT, firewalling and DHCP amongst other duties. This infrastructure was also shared with the OWL Visitor service.
It is perhaps noteworthy to mention that all this was originally designed and commissioned back in 2008. Since then, some efforts have been made (where possible) to improve the OWL/eduroam service for users. These have been relatively minor improvements such as slightly increasing infrastructure resiliency by adding an additional link to another egress backbone router in the topology, upgrading fast-ethernet links to gigabit-ethernet ones and more recently in April 2012, the per-user bandwidth cap was relaxed from 2Mbps to 8Mbps. So to be clear, it’s not quite the same service as it was from day one!
Perhaps worth a mention too is that the NetEnforcer appliance over its life has proven expensive to license and support. Therefore its days have been numbered for some time.
This has all worked just fine for the most part, though we believe we have been ‘living on borrowed time’ to some extent with this infrastructure and as a result have reminded relevant parties in the past that without investment, the infrastructure could start to creak under the weight of more and more mobile clients coming online and the eduroam service growing more popular as a result.
Unfortunately, our fears became reality when we began to receive complaints of poor performance back in February. We could see from some reports that users were struggling to achieve their allotted 8Mbps download speeds (perhaps getting 2Mbps or less in some severe instances). Further investigation using our monitoring tools confirmed that the combined downstream OWL/eduroam traffic hitting our backend infrastructure had started to saturate the gigabit-links resulting in many users having to contend heavily for bandwidth. As we continued to monitor the situation, we discovered that the links were topping out regularly at around 970Mbps at various times of the day and this helped us to confirm that this was more a problem of scale – that is, lots more users now using the service rather than there being a minority of users or units/departments ‘swamping’ the service.
Quick-fix?
We considered (and quickly dismissed you’ll be glad to hear) tightening the per-user bandwidth cap to ease the pain for all users.
We also investigated the possibility of bundling together multiple gigabit links in the existing infrastructure and upgrading relevant components within the hardware. However we reached the conclusion that doing any of this was still likely to involve significant configuration and manual effort, pose the risk of unscheduled downtime to a working (albeit congested) service and only postpone an inevitable infrastructure upgrade. Especially considering the age of some of this hardware and how long it had been running for (one of the network switches was showing an uptime of 4 years, 43 weeks, 3 days, 4 hours, 8 minutes uptime at the time of writing to give you an idea).
Notably, any quick-fix also would not have addressed some of the Single Points-of-Failure (SPoF) with the existing infrastructure. The most notable ones being:
- Network switch failure (no modular internal PSUs in the 3560G & no redundant power capability);
- Local power failure in cabinet;
- Failure of the primary JANET border router (JOUCS1);
- Power failure of Banbury Road Data Centre (BR DC).
Also there were other aspects about the old infrastructure I was not too keen on. Individual links that failed would mean a topology change and the use of RIPv2 for L3 routing wasn’t ideal in my mind. To manually initiate a failover from the active to the standby firewall meant manipulating offset lists to change the number of hops of routes to effectively ‘sour the milk’. I really wanted to find a simpler solution moving forward.
It’s project time!
Therefore a project was initiated. This meant that some colleagues and I within the Networks team were given an ambitious deadline (beginning of Trinity term 2014) and a limited budget to design, build and commission a new infrastructure to provide an improved eduroam service.
With these constraints in mind, the aims of the project were to build a new backend infrastructure that:
- Replaced the ageing server & networking hardware;
- Provided an alternative solution for user rate-limiting;
- Provided improved resiliency & reduced SPoFs;
- Didn’t require any significant re-engineering of the university backbone or customer FroDo switches;
- Removed current bottlenecks & provided extra capacity to scale to user demands over the next few years.
None of these aims may seem particularly unusual or ‘out there’, however the last point bears some extra consideration. I would argue that successfully meeting this aim given the devolved nature of the university and its collegiate units & departments was always going to be extremely difficult and will likely remain so.
Why? Well what this effectively means is that whilst it’s possible for us here in IT Services to get a feel for the numbers of users making use of the eduroam service today and therefore get some idea of traffic levels (things like the provisioning of self-managed ports & associated networks on the FroDos, the central wireless service & our monitoring tools aid us here). It is much, much more difficult for us to forecast this moving forward, that is to say, we aren’t made aware directly, for example, when a large number of users in unit A or department B are about to make use of the eduroam service. This by its very nature, makes things very hard to forecast and in-turn, makes capacity-planning a game of cat-and-mouse.
Also bear in mind at this point that all we really knew was that the existing gigabit infrastructure wasn’t cutting the mustard. We didn’t *really* know what the traffic levels would be like once we had fitted the ‘bigger pipes’ if you will.
The design
So, we decided we should improve things by an order of magnitude to be as safe as possible. This meant a decision to procure new network switches and server hardware (covering aim 1 above) that should at a minimum be ten-gigabit-ethernet capable (hopefully helping to covering aim 5). Now this all seems generally straightforward and there were potentially options from various vendors that could have met our networking requirements here. However, given aim 4 above and the relatively short timescale to deliver the new solution, we decided to stick with our incumbent Cisco. Coupled with aim 3 above, this resulted in the design depicted below:
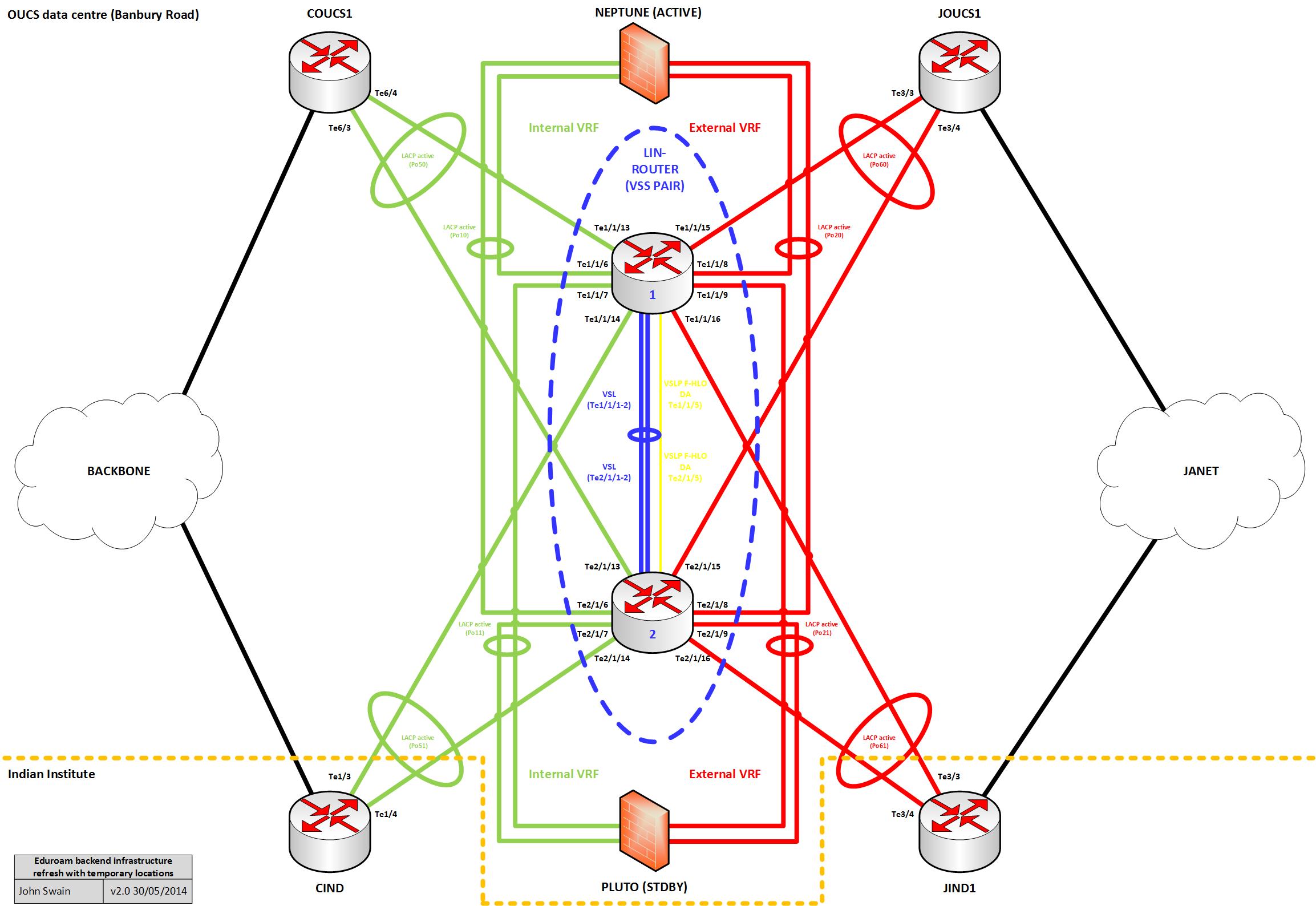
The use of Multi-chassis EtherChannels (MECs) throughout the design based on two physical ten-gigabit links, each connected to a single Cisco Catalyst 4500-X switch and aggregated logically together would ensure resiliency against the loss of one link. Logically grouping the two switches into a Virtual Switching System (VSS) pair would also help guard against the failure of one switch taking out our new infrastructure. We also decided to specify the switches with dual-PSUs to further improve resiliency at the hardware-level.
It was decided to use Single-Mode Fibre (SMF) and Long-Range (LR) optics to hang everything together. We could have instead opted to use Multi-Mode Fibre (MMF) with Short-Range (SR) optics or even copper UTP or Direct-Attach media for some connections. Whilst using LR optics & SMF throughout the topology would inevitably make things more expensive, when weighed against the added flexibility it would bring we decided it would be worth it in the longer-term. This is because our intention is to eventually dual-site all of this equipment in two separate MDX rooms around the city.
Sadly we weren’t able to dual-site everything in the initial deployment because of the lack of SMF infrastructure capacity at the time (we are promised this will change in the future mind you), though it has meant we have been able to add resiliency for the standby path using the local backbone and border routers housed at the Indian Institute MDX facility (CIND & JIND1).
The 4500-X platform (running IOS-XE) was new to us, but VSS technology itself wasn’t as we have implemented this elsewhere in our estate on the Supervisor 2T (running IOS) so we were relatively confident of its capabilities.
This is what the design looked like from a logical L3 perspective:

Overall the design is active/standby, such that the top half of the logical diagram represents the active path which should be used under normal circumstances, and the bottom half is the standby, or backup path.
‘Inside’ and ‘outside’ L3 routing would be kept logically separate in the new design by using Virtual Routing & Forwarding (VRF) instances. This is in place of using separate network switches to provide this function. We opted to use static routing in conjunction with the IOS object-state tracking feature to control path selection and provide a failover mechanism.
So with the design signed-off, it was time to order, procure and obtain the new hardware & licensing necessary to make it all happen.
The initial installation & testing
Before the equipment arrived, we were able to design and test some things using a mock-up of the design based on some old Cisco switches and development hosts we had in a lab environment which assisted tremendously whilst we waited anxiously for the cardboard boxes to arrive. Though notably, meaningful testing of the new topology and all of the underlying technologies we intended to use would only be possible once the new equipment had arrived.
The equipment arrived in stages throughout March/April, which sadly shattered the original deadline given and put us under additional pressure to build the new infrastructure quickly. Towards the end of April, we had a working infrastructure installed and running. This then meant we could migrate a test backbone router with some test FroDos to start the important final testing. It would be this last piece of work that would contribute heavily towards tweaking what would become the final solution.
User bandwidth rate-limiting
Three candidate solutions that could have potentially fulfilled our requirement here were considered which I’ve listed below in our order of preference:
- Queuing methods using the Linux hosts in our infrastructure;
- User-Based Rate-Limiting (UBRL) on the Cisco switches using ‘Microflow’ policing;
- User rate-limiting via the central WLCs with unit/department self-managed WLC deployments encouraged to do the same.
My colleague Christopher spent a considerable amount of time testing option 1. In a nutshell, this was eventually rejected because we weren’t confident we could get this to scale well to the number of client devices that would eventually be using the service. Well, not within the short timescale we had left to deploy the new infrastructure anyway.
Frankly, I initially had similar concerns with option 2 though this is what we opted for in the end. Microflow policing is used to limit user traffic per inside client IP symmetrically to approximately 8Mbps and this seems to work very well.
Option 3 would have been our fallback position. My colleague Rob had tested rate-limiting clients using the Cisco WLCs before so we were relatively confident that this would have worked for units with centrally-managed APs. Of course, in light of many units opting to run their own self-managed WLC & AP deployments out of our administrative control, this would have also relied on these systems having similar controls implemented. Any not doing so could have introduced the risk of having an adverse impact on the new infrastructure and potentially on their backbone connectivity from their local FroDo too. In all honesty, we wouldn’t have been happy with this option given that we also wanted to do our best to prevent any contention issues happening at the FroDo and local LAN level too.
Moving into production
Migrations were performed per backbone (C) router. We started slowly with the two routers based here in IT Services (COUCS1 & COUCS2). The first big migration was the CIHS router serving the hospitals and medical units over in Headington. This migration revealed some performance issues with our Linux hosts which Christopher rectified relatively quickly. The remaining migrations were completed w/c 19th May.
How is it looking so far?
The short answer, very good.
The longer answer is that our monitoring has so far shown we’re regularly seeing traffic levels >1Gbps across the new infrastructure since the migrations were completed. The highest peak at the time of writing was in the order of approximately 1.5Gbps. Just so we’re crystal clear, these figures I’m quoting are for eduroam traffic only. OWL Visitor is still running on the previous infrastructure and we’ve seen peaks for this traffic of around 250Mbps since de-coupling the two services. Why is this relevant now? Well I use it for illustration purposes because these services used to share the same gigabit infrastructure. It’s hardly a wonder with hindsight that the traffic from both of these services combined on the old infrastructure was causing performance blight for eduroam users!
Thoughts moving forward
Whilst our new infrastructure is ten-gigabit-capable (actually double this if you take the MECs into account you could say), it is largely unknown as to how well the Linux hosts will perform under high-load and this is what we’ll be watching for in the coming months (especially at the start of the new academic year).
I’ve had some thoughts on using Policy-Based Routing (PBR) on the Cisco switches to provide us with an active/active scenario to spread the load evenly over both paths in the design and ease the load on a single Linux host. This is an improvement we could engineer to improve things in the near future if things start to look bleak once again.
Overall I can say that we in the eduroam upgrade project team are very proud of what we’ve achieved so far with limited time, money and resources.
LONG LIVE NEW EDUROAM!