People within Oxford University may be aware that the eduroam service has recently been upgraded to increase its bandwidth, which was saturated on the old infrastructure. This included the replacement of two Linux servers which provide services key to the successful running of eduroam. Much of what was done involved porting the old setup to new hardware, but we took the opportunity to improve the resiliency and tie up a few loose ends. This series of blog posts will seek to explain our new setup, some hurdles that we encountered while upgrading and some useful guiding blog posts and documentation we used.
The upgrade included an upgrade of the switches that sit either side of the Linux boxes (from two independent Cisco 3560 switches to two Cisco Catalyst 4500-X switches set up as a VSS pair) they warrant a series of posts of their own, which are being written by John Swain, and are being published concurrently with this series. There will be some overlap in the coverage but you may read either series in isolation, depending on what interests you.
The setup
Eduroam is a location independent service; whether you’re sat in the Bodleian library or in the John Radcliffe hospital, when you connect to the eduroam wireless SSID, the traffic generated eventually ends up going through one of two Linux servers (configured as an active/standby pair) which NAT the traffic, and route it via some dedicated networking infrastructure and onwards via janet to its destination. For a network the size of Oxford University’s eduroam, this is quite a feat in itself that I can claim absolutely no credit for (it was like that when I got here.)
The Linux servers’ roles in all of this are the following:
- NAT – eduroam clients are assigned private IP addresses and so they need to be translated to a public IP before being given to janet.
- DHCP – eduroam clients need unique addresses. One of a DHCP server’s roles is to ensure this is true by assigning addresses uniquely per client connected.
- DNS – resolving a hostname (e.g. www.ox.ac.uk) to an IP address. This isn’t currently done by these boxes but they may do it in the future.
- Logging – we log connections to assist with cease and desist requests.
NAT is the primary focus of this first blog post.
Network Address Translation
What is it?
The IP address assigned to an eduroam client is from an RFC1918, or private, address range. An example is 10.16.1.1 which can be found on the network 10.16.0.0/23. This means that while the client can in theory talk to other clients on the same range, for example 10.16.1.2, access to external sites, such as www.google.com, www.bbc.co.uk and even www.ox.ac.uk is not possible. What the client needs is a public IP address so that when it talks to the outside world’s public IP addresses, the outside world knows where to send a reply. In an ideal world everyone would have a unique public address, but this isn’t an ideal world. There are 4.3 billion IP addresses to be shared amongst 7 billion people and until a new IP standard comes along (IPv6 is just around the corner, and has been for years) we will have to make do with sharing public IPs so multiple private addresses use the same public address. It is the job of a Network Address Translation (NAT) server to translate a range of private addresses (e.g. 10.16.1.1, 10.16.1.2) to a public (e.g. 192.76.8.1) address. When you contact an external site, such as www.ox.ac.uk, the NAT server translates your address from private to public, and hands the request to www.ox.ac.uk.
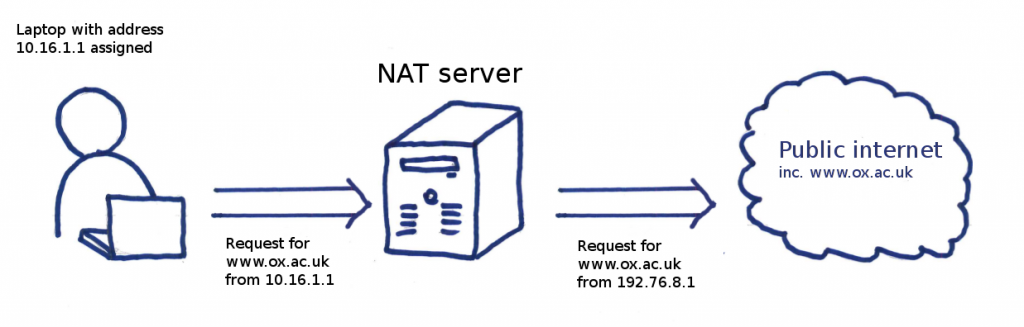
A client making a request on eduroam
The www.ox.ac.uk web server replies, sending the reply to the NAT server, which translates the address back to the private one and you eventually get back the response to the original request.
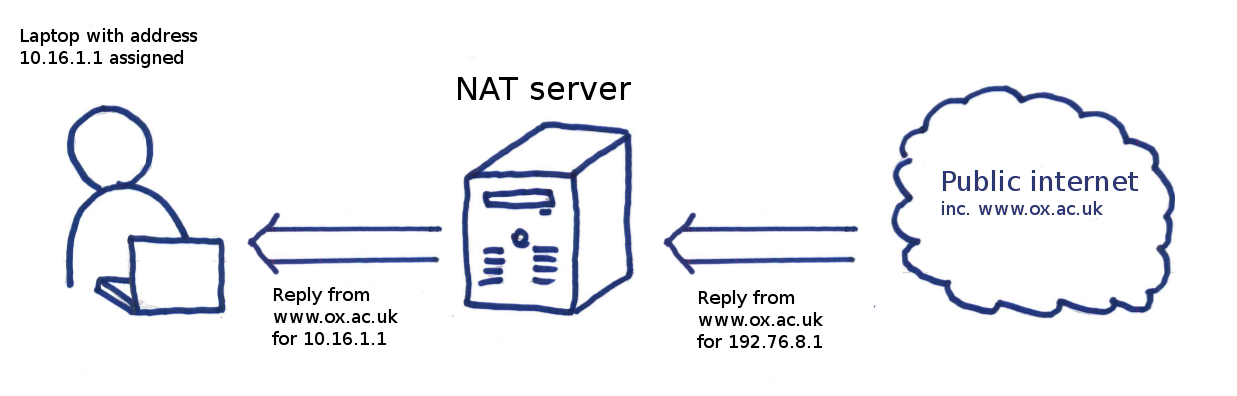
The response from an external host
Some people might point out that I have just described PAT (port address translation) rather than NAT because NAT is not strictly address sharing. To those people I would say that you are correct, but I will still be referring to it as NAT for the remainder of this post as the meanings have become so blurred that not many people would be able to make the distinction.
Initial setup – Turning on packet forwarding.
Linux does not forward packets by default, which is what we require it to do. That is to say a Linux box will only accept packets if they are destined for the box itself. The following command will turn packet forwarding on:
echo "1" > /proc/sys/net/ipv4/ip_forward
Adding the line to your rc.local will mean that forwarding will be on the next time you reboot (otherwise it will reset.) We do things slightly differently for our NAT server, but only for historical reasons and the end result is the same as using the line above.
How can you implement it?
Most people implement NAT on Linux using iptables rules, a userspace frontend to the Linux kernel’s netfilter framework. When people talk of iptables, they usually are referring to its IP packet filtering capabilities. However, iptables can do much more, from NAT as we are doing here to even editing the packet header to implement some form of QoS.
In most small scale NAT deployments, the server has two addresses, one on the “inside” (usually on a private address range), the other on the “outside” (usually a public address). The private address is the gateway used by the clients, so traffic not for the current network ends up on the NAT box. This will be the lion’s share of the traffic. For example, a NAT box which has an address of 10.16.1.254 on its eth0 interface (the private network in this instance could be 10.16.0.0/23) and a public address of 192.76.8.1 connected via eth1. A simple rule on the NAT server so that clients on the 10.16.0.0/23 network can connect to the outside world would then be:
iptables -t nat -A POSTROUTING -s 10.16.0.0/23 -o eth1 -j MASQUERADE
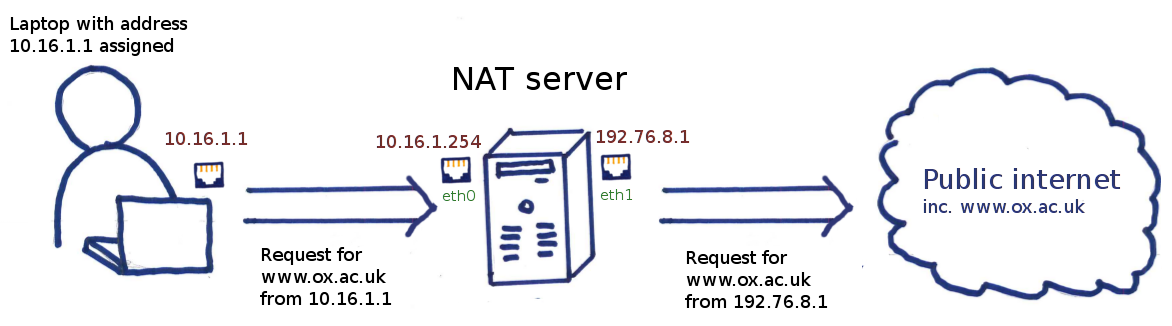
What happens when you use MASQUERADE
I will not be explaining the individual flags required for iptables. The iptables man pages are very good and searching through them for things such as “POSTROUTING” and “-s” will explain their purpose very clearly.
Now, assuming that your routing to, from and in the NAT box is correct (routing using Linux will be covered in a later post), if a laptop with an IP address of 10.16.1.1 attempts a connection to www.ox.ac.uk, the packets would be end up on the NAT server. The NAT server would then change the source address from 10.16.1.1 to 192.76.8.1 and send it out its public interface (eth1). The request would reach the Oxford University webserver, which would reply to the NAT server thinking it was that server that made the request. The NAT box, knowing better will receive the reply destined for 192.76.8.1, translate it back to 10.16.1.1 and forward it to the eduroam connected device.
How does the Linux kernel know that a particular reply from www.ox.ac.uk addressed to 192.76.8.1 needs to be rewritten to 10.16.1.1 and not 10.16.1.2? A full answer is going to be in a follow-up post but in short, Linux has a connection tracking system, called conntrack.
What’s the problem with this implementation?
While this will work in most environments, there is a limitation: Since our records have shown over 30,000 devices connected simultaneously in the past, there is real possibility of exhausting a single public IP’s 65535 source ports (ignoring the messy possibility of port overloading, where two connections share the same public IP address and source port.)
What our eduroam NAT implementation should do is use a range of addresses for the translated source address. In our case we have allocated 192.76.8.0/26 for the purpose.
Kernels up to 2.6.10 allowed for the following line which specifies a range of addresses to which the traffic can be translated:
# Don't do this
iptables -t nat -A POSTROUTING -s 172.16.1.0/24 -o eth1 -j SNAT \
--to-source 192.76.8.1-192.76.8.62
This isn’t allowed any more, and for good reason. Some programs assume that consecutive connections from the same client have the same public IP address. This isn’t guaranteed with the line above. One time I may have the address 192.76.8.2, another I may have 192.76.8.4. In other words, the source address as seen by the external host is non deterministic.
I should note at this point that in the simple example above using MASQUERADE, the address 192.76.8.1 was an address that the Linux host had assigned to its interface (running “ip addr list” would have shown that address). Any traffic destined for 192.76.8.1 will not be forwarded unless the connection was started by a computer on the private address range. In other words, packets addressed to 192.76.8.1 can be terminated on the server itself. However, in the case of NAT traffic, the kernel’s connection tracking will kick in and know that the packets need to be forwarded. For our actual real world example below, the address range 192.76.8.0/26 is not on the host at all. The packets end up on the host by static routing and when they end up on the Linux box, they will be forwarded by default, stopped only by whatever rules you have in place in your FORWARD iptables chain.
Using an address range is the obvious solution, but there are a few things that you need to worry about:
- Predictability: When you’re connected to the network, you don’t want your public IP as seen by the outside world to change regularly.
- Load sharing: The public ip addresses should be utilized as evenly as possible.
These requirements seem obvious. The first requirement effectively necessitates that the mapping is based on private source IP. Splitting up the source IPs into evenly utilised sets of IPs (not necessarily subnets) to satisfy the second requirement is what the remainder of this post is about.
The u32 iptables module
To skip to the punchline, here is a snippet from our NAT configuration:
iptables -A POSTROUTING -s 10.16.0.0/12 -o bond1 -m u32 \
--u32 "0xc&0xff=0xeb:0xef" -j SNAT --to-source 192.76.8.48
iptables -A POSTROUTING -s 10.16.0.0/12 -o bond1 -m u32 \
--u32 "0xc&0xff=0xf0:0xf4" -j SNAT --to-source 192.76.8.49
Ignore the -o bond1 for a moment (that is link aggregation, a topic for another post). The eduroam address range, as shown above, is 10.16.0.0/12. This means that at any one time we have the potential to have over 1,000,000 clients connected. In practice we don’t as the IP allocations are subdivided based on various criteria (the college or department, for example), but the result is that some portions of this address space are fairly densely populated while others are unused. Splitting up the /12 subnet into smaller subnets would thus be unworkable as we would create hotspots.
For example, if we’d written something like
iptables -A POSTROUTING -s 10.16.0.0/16 -o bond1 -j SNAT \
--to-source 192.76.8.48
iptables -A POSTROUTING -s 10.17.0.0/16 -o bond1 -j SNAT \
--to-source 192.76.8.49
and the 10.17.0.0/16 network is unused, we would have wasted a precious public IP address.
A much better mechanism for sharing the traffic evenly on our eduroam addressing scheme is by the last octet, so x.x.x.1 is translated to one source IP address, while x.x.x.8 is translated to another.
Going back to our example lines, the important bit to notice is the fairly cryptic ‘--u32 "0xc&0xff=0xeb:0xef"' What we are doing here is we are using the u32 module of iptables, which allows you to create rules based on the contents of any consecutive 32 bits (or part thereof) of an IP packet. The source IP address is located 12 bytes into the header (which in hexidecimal [hex] notation is “c”). The u32 module then extracts the next 32 bits (aka 4 bytes), but since we only care about the last byte of the source IP (an IPv4 address takes up 4 bytes), we mask the rest so that they are 0. We then check to see if they are in the range eb to ef, or 235 to 239 in decimal notation.
Rewriting the rule in something more friendly to perl programmers, we would have
# By default, perl works at the character level. We # want substr to extract at byte boundaries. use bytes; # Extracting the $SOURCE_IP from the packet using # the u32 module cannot really be represented # in perl code. This is an attempt to convey what it might # look like. This takes 4 bytes out of $IP_PACKET, starting # at the 0xc byte. $SOURCE_IP = substr $IP_PACKET, 0xc, 4; # The 0xff in the iptables rule above would perhaps # become clearer if written explicitly showing what bits # it is masking (i.e. setting to zero.) $LAST_OCTET_MASK = 0x000000ff; # When you bitwise AND two numbers, you put the two numbers on top # of each other (in binary notation), note when two 1 digits # align, and make that digit in the output 1. Otherwise it's 0. # # For our example, our two input numbers are the $SOURCE_IP and # $LAST_OCTET_MASK which when bitwise ANDed, # create a number that every bit in the $SOURCE_IP # is set to zero except the last octet. For example, here # is an IP address of 12.34.56.78: # # 0x000000ff <= $LAST_OCTET_MASK # &0x12345678 <= $SOURCE_IP # ========== # 0x00000078 # # The numbers are written in hex here but the principle is the # same: when it's an f in the $LAST_OCTET_MASK, the result contains # the digit of the other row. If it's 0, then the result's digit # is 0 as well, regardless of what is in the $SOURCE_IP. $LAST_OCTET = $SOURCE_IP & $LAST_OCTET_MASK; # The IP rule matches if the last octet is between # the two ranges. The match_iptables_rule() is again a # representation of the -j SNAT .... match_iptables_rule() if $LAST_OCTET >= 0xeb and $LAST_OCTET <= 0xef;
Are there other ways of doing it?
Absolutely!
ipset
Be warned that the following is what I would have done. I haven’t actually tested this and while I don’t foresee the following not working for us, I wouldn’t say with any confidence that what I’ve written would work without modification.
The ipset module is traditionally used (to great effect) to collapse a long list of similar rules. Say you wanted to recreate the NAT scheme above, only using vanilla iptables rules (i.e. no modules.) It would look something like (simplified for brevity.)
iptables -A POSTROUTING -s 10.16.0.1 -j SNAT --to-source 192.76.8.1 iptables -A POSTROUTING -s 10.16.1.1 -j SNAT --to-source 192.76.8.1 iptables -A POSTROUTING -s 10.16.2.1 -j SNAT --to-source 192.76.8.1 ... iptables -A POSTROUTING -s 10.16.255.1 -j SNAT --to-source 192.76.8.1 iptables -A POSTROUTING -s 10.16.0.2 -j SNAT --to-source 192.76.8.1 iptables -A POSTROUTING -s 10.16.1.2 -j SNAT --to-source 192.76.8.1 iptables -A POSTROUTING -s 10.16.2.2 -j SNAT --to-source 192.76.8.1 ... iptables -A POSTROUTING -s 10.16.255.7 -j SNAT --to-source 192.76.8.1 iptables -A POSTROUTING -s 10.16.1.8 -j SNAT --to-source 192.76.8.2 .....
In total, there would be one rule per source IP address, or 1048574 rules. The person with IP address 10.31.255.254 would have reason to be annoyed because every packet from that address would have to be checked on each rule, causing significant delay in the processing of the packet (iptables rules are checked in sequence until the first match.)
Of course in reality nobody would be crazy enough to do this, but the same effect can be achieved using ipset. First, you create some sets
ipset -N octets-1-to-7 iphash ipset -N octets-8-to-14 iphash ...
Then you add the relevant addresses to the set
# Script to add ip addresses to sets. In reality you would use # "ipset restore", but that is harder to read, so in the interests # of clarity the following adds IP addresses to sets individually for second_octet in $(seq 16 31); do for third_octet in $(seq 0 255); do for fourth_octet in $(seq 1 7); do # Add IP address 10.$second_octet.$third_octet.$fourth_octet # to ipset octets-1-to-7 ipset -A octets-1-to-7 10.$second_octet.$third_octet.$fourth_octet done for fourth_octet in $(seq 8 14); do ipset -A octets-8-to-14 10.$second_octet.$third_octet.$fourth_octet done # Same for other sets ... done done ...
You then add the line in your iptables
iptables -t nat -A POSTROUTING -m set --set last-octet-1-to-7 src \
-j SNAT --to-source 192.76.8.1
iptables -t nat -A POSTROUTING -m set --set last-octet-8-to-14 src \
-j SNAT --to-source 192.76.8.2
...
Now you might wonder what you’ve gained here. At first glance it looks like all you’ve done is move an IP match in iptables into a match in ipset. In one sense, that is exactly what has happened, but the key here is the word “iphash” when we created the sets. This means that the IP addresses are stored in a hash table and looking up any one IP address for membership of the set is quick, independent of the IP address being matched, and more importantly the number of IP addresses in the set (within reason).
This method has the advantage over u32 in that you have ultimate control over your source based NAT tables. Don’t want to NAT an address when the last octet is a prime number? Sure, just write that into the script above! Is a public IP too heavily utilized? Not a problem, just move some IPs around from one set to another. There wouldn’t even be any downtime as updates to the ipset sets are atomic unlike lengthy iptables builds which can take a noticeable amount of time.
There are two downsides, although both are minor. The first one is that it takes up memory, but, as a very rough calculation, an IP address is 4 bytes, so to store every IP address in the eduroam network in memory would take roughly 4MB, or 3.8 × 10-7 Libraries of Congress. The ipset command can tell you how much memory it uses for each set created, which shows that if we were to use this, its memory usage wouldn’t be too far off this figure (14MB on our development server). The second one is that it takes a little time to build the hash tables. Again on our development server, it takes around 17 seconds to load all ip addresses in the 10.16.0.0/12 range (by using ipset restore < ipset-file. Using the script above would take over an hour.) Whether you’re happy with that depends on how long you’re happy to wait after every reboot.
Starting with a clean slate, I would probably have picked the ipset module over the u32 module. The main advantage that the u32 module has was that it was already in use on the old eduroam servers so less had to be done to get that working. Why u32 was chosen over ipset for the original eduroam implementation is not a question I can definitively answer but it would most likely be because the ipset module was not as widely known (it certainly wasn’t in the Debian repository) during the initial eduroam deployment.
What’s next?
This concludes a brief overview of NAT and its role in eduroam. Next up is a post on routing tables.