While this is superficially a post for creating an upsert PostgreSQL query for FreeRADIUS’s sql_log module, I felt the problem was general enough to warrant an explanation as to what CTEs can do. As such, the post should be of interest to both FreeRADIUS administrators and PostgreSQL users alike. If you’re solely in the latter camp, I’m afraid that knowledge of the FreeRADIUS modules and their uses is assumed, although the section you’ll be most interested in hopefully can be read in isolation.
The problem
All RADIUS accounting packets received by our RADIUS servers are logged to a database. Previously we used the rlm_sql module included with FreeRADIUS to achieve this, which writes to the database directly as a part of processing the authentication/accounting packet.

When using rlm_sql, a RADIUS packet arrives at the FreeRADIUS server, it is immediately logged in the database.
However, we decided to change to using rlm_sql_log, (aka the sql_log module) which buffers queries to a file for processing later via a perl script.
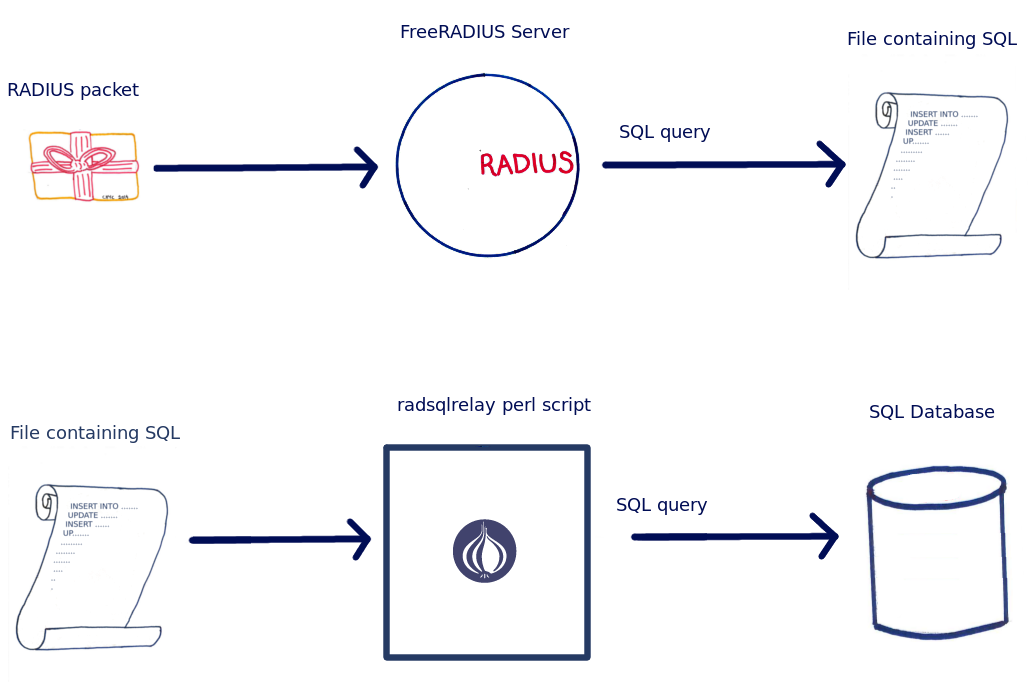
rlm_sql_log buffers queries to a file before executing at a later date.
At the expense of the database lagging real life by a few seconds, this decouples the database from the FreeRADIUS daemon completely and any downtime of the database will not affect the processing of RADIUS packets. Another benefit is that rlm_sql requires as many database handles (or database connections) as packets it is processing at any one time. For us that was 100 connections per server, which almost certainly would be inadequate now that our RADIUS servers are under heavier load. Using rlm_sql_log we now have one connection per server.
However, the rlm_sql module had a nice feature we used where update (eg. Alive, Stop) packets would cause an update of a row in the database but if the row didn’t exist one would be created. If you look at the shipped configuration file for sql_log, you will see that this behaviour is not available as a configuration parameter and every packet results in a new row in the database, even if a previous packet for the same connection has already been logged. The reason that it chooses to do this is fairly obvious: there is no widely implemented SQL standard which defines a query that updates a row, and inserts a new one if it doesn’t exist. MySQL has its own “ON DUPLICATE KEY UPDATE…”, but we use PostgreSQL and even if we did use MySQL, such a mechanism would not work without modification to FreeRADIUS’s supplied schema.
One could in theory change the INSERT statements for UPDATE statements where appropriate (i.e. everything but the start packet), but bear in mind that RADIUS packets are UDP, and as such their delivery isn’t guaranteed. If the start packet is never received, then UPDATE statements will not log anything to the database.
The solution
Common Table Expressions

The IT Services United Crest
The SQL 1999 spec defined a type of expression called a Common Table Expression [CTE]. PostgreSQL has been able to use these expressions since 8.4 and, although not sold as such, they are a nice way of simulating conditional flow in a statement, by using subqueries to generate temporary tables which affect the outcome of a main query. Said another way, a simple INSERT or UPDATE statement’s scope is limited to a table. If you want to use one SQL query to affect and be based upon the state of multiple tables without using some kind of glue language like perl, this is the tool to reach for
The official documentation contains some examples, but I will include my own contrived one for completeness.
Say a professional football team existed, IT Services United. Each player for the purposes of this exercise has two interesting attributes, a name and a salary, which could potentially be based on the player’s ability. In a PostgreSQL database the table of players could look like the following:
Table "blog.players"
Column | Type | Modifiers
--------+-------------------+-----------
name | character varying | not null
salary | money | not null
Indexes:
"players_pkey" PRIMARY KEY, btree (name)
Check constraints:
"players_salary_check" CHECK (salary > 0)
If you wanted to give everyone a 10% raise, that’s not too difficult:
UPDATE players SET salary = salary * 1.1;
So far so good. Now, as most people can attest I am not great at football, so everyone else on the team deserves a further raise as recompense.
UPDATE players SET salary = salary * 1.2 WHERE name != 'Christopher';
On the face of it this query should be sufficient. However there are deficiencies. I may not be playing for IT Services United (I may have recently signed for another team), in which case the raise is unjustified. Also this money has to come from somewhere. We should be taking this money out of my salary as this is being done as a direct consequence of my appalling skills on the pitch.
In summary we would like to do the following:
- Check to see if I’m a player, and do nothing if I’m not
- Find the sum of the salary increase for all players excluding me
- Deduct this sum from my salary
- Add this to each player accordingly
Doing this in one query is not looking so simple now. People normally faced with this scenario would use a glue language and multiple queries, but we are going to assume we do not have that luxury (as is the case when using rlm_sql_log).
There are other things to consider as well:
- Rounding is an issue that cannot be ignored especially when it comes to money. For the purposes of this example the important number the total outgoing salary given to the team, SUM(salary), is constant but this would need much more scrutiny before I used this for my banking say.
- The problem of negative salaries has already been taken care of as a table constraint (see the table schema above). If any part of the query fails, then the whole query fails and there is no change of state.
Here’s a query that I believe would work as billed:
WITH salaries AS ( UPDATE players SET salary = players.salary * 1.2 -- ← Boost salary of the players FROM players p2 -- |Trick for getting WHERE -- ←|original salary players.name = p2.name -- |into returning row AND -- ↓ Check I'm playing ↓ exists ( select 1 from players where name = 'Christopher') AND players.name != 'Christopher' -- ← I don't deserve a raise RETURNING -- |RETURNING gives a SELECT like players.salary AS new_salary, -- ←|ability, where you create p2.salary AS original_salary, -- |a table of updated rows. players.salary - p2.salary AS salary_increase ) UPDATE players -- ↓ Deduct the amount from my salary ↓ SET salary = salary - (SELECT sum(salary_increase) FROM salaries) WHERE name = 'Christopher';
For people who dabble in SQL occasionally this query might seem a bit dense at first, but the statement can be made clearer if broken down into its components. Here are some that deserve closer scrutiny:
- WITH salaries AS (………)
- This is the opening and the main part of CTEs. It basically says “run the query in the brackets and create a temporary table called salaries with the result.” This table will be used later
- UPDATE …… RETURNING ….
- UPDATE statements by default only shows the number of rows affected. This is not much use here so adding “RETURNING ….” to the statement returns a table of the updated rows with the columns you supply in the statement. This becomes the salaries table.
- UPDATE …. FROM ….
- When using RETURNING, unfortunately you cannot return the values of the row prior to its update. However, you are allowed to join a table in an update statement using FROM. In this example we are using a self join to join a row to itself! When the row is updated the joined values are unaffected by the update and can be used to return the old values.
- SET salary = salary – (SELECT sum(salary_increase) FROM salaries)
- Each individual
salary_increaseis in the temporary tablesalaries, but we need the sum of these values. Because of this we need to use a subquery within the second update statement.
This example is so contrived as to be silly, but you can see how we have been able to effectively use one query to affect the outcome of another. In our FreeRADIUS sql_log configuration, our requirements could be satisfied by the following logic:
- Run an update statement , returning a value if successful
- Run another query (an insert statement) if the value from the previous query is a certain value
This type of query has its own name, which if you couldn’t guess by the title of this post is “upserting”. There are numerous people asking for help with this for PostgreSQL on StackExchange and its ilk.
Indeed it is such a highly sought feature that a special query syntax for upserting looks to be coming in PostgreSQL 9.5. However 9.4 hadn’t even been released when the new servers were deployed and I didn’t even know this was on 9.5’s roadmap at that time (and I wouldn’t have waited in any case). Also the 9.5 functionality isn’t quite as flexible, and the queries would not be equivalent to the ones we actually use, but they probably would be close enough that we’d use them anyway.
The sql_log config file
Presented warts and all are the relevant statements that we use in our sql_log configuration for FreeRADIUS 2.1.12. It isn’t pretty, but I doubt it can be, especially in the confines of this blog site’s CSS. They are to be copy and pasted rather than admired:
Start = "INSERT into ${acct_table} \
(AcctSessionId, AcctUniqueId, UserName, \
Realm, NASIPAddress, NASPortId, \
NASPortType, AcctStartTime, \
AcctAuthentic, AcctInputOctets, AcctOutputOctets, \
CalledStationId, CallingStationId, ServiceType, \
FramedProtocol, FramedIPAddress) \
VALUES ( \
'%{Acct-Session-Id}', '%{Acct-Unique-Session-Id}', '%{User-Name}', \
'%{Realm}', '%{NAS-IP-Address}', NULLIF('%{NAS-Port}', '')::integer, \
'%{NAS-Port-Type}', ('%S'::timestamp - '1 second'::interval * '%{%{Acct-Delay-Time}:-0}' - '1 second'::interval * '%{%{Acct-Session-Time}:-0}'), \
'%{Acct-Authentic}', (('%{%{Acct-Input-Gigawords}:-0}'::bigint << 32) + '%{%{Acct-Input-Octets}:-0}'::bigint), \
(('%{%{Acct-Output-Gigawords}:-0}'::bigint << 32) + '%{%{Acct-Output-Octets}:-0}'::bigint), \
'%{Called-Station-Id}', '%{Calling-Station-Id}', '%{Service-Type}', \
'%{Framed-Protocol}', NULLIF('%{Framed-IP-Address}', '')::inet );"
Stop = "\
WITH upsert AS ( \
UPDATE ${acct_table} \
SET framedipaddress = nullif('%{framed-ip-address}', '')::inet, \
AcctSessionTime = '%{Acct-Session-Time}', \
AcctStopTime = ( NOW() - '1 second'::interval * '%{%{Acct-Delay-Time}:-0}' ), \
AcctInputOctets = (('%{%{Acct-Input-Gigawords}:-0}'::bigint << 32) + '%{%{Acct-Input-Octets}:-0}'::bigint), \
AcctOutputOctets = (('%{%{Acct-Output-Gigawords}:-0}'::bigint << 32) + '%{%{Acct-Output-Octets}:-0}'::bigint),\
AcctTerminateCause = '%{Acct-Terminate-Cause}', \
AcctStopDelay = '%{Acct-Delay-Time:-0}' \
WHERE AcctSessionId = '%{Acct-Session-Id}' \
AND UserName = '%{User-Name}' \
AND NASIPAddress = '%{NAS-IP-Address}' AND AcctStopTime IS NULL \
RETURNING AcctSessionId \
) \
INSERT into ${acct_table} \
(AcctSessionId, AcctUniqueId, UserName, \
Realm, NASIPAddress, NASPortId, \
NASPortType, AcctStartTime, AcctSessionTime, \
AcctAuthentic, AcctInputOctets, AcctOutputOctets, \
CalledStationId, CallingStationId, ServiceType, \
FramedProtocol, FramedIPAddress, AcctStopTime, \
AcctTerminateCause, AcctStopDelay ) \
SELECT \
'%{Acct-Session-Id}', '%{Acct-Unique-Session-Id}', '%{User-Name}', \
'%{Realm}', '%{NAS-IP-Address}', NULLIF('%{NAS-Port}', '')::integer, \
'%{NAS-Port-Type}', ('%S'::timestamp - '1 second'::interval * '%{%{Acct-Delay-Time}:-0}' - '1 second'::interval * '%{%{Acct-Session-Time}:-0}'), \
'%{Acct-Session-Time}', \
'%{Acct-Authentic}', (('%{%{Acct-Input-Gigawords}:-0}'::bigint << 32) + '%{%{Acct-Input-Octets}:-0}'::bigint), \
(('%{%{Acct-Output-Gigawords}:-0}'::bigint << 32) + '%{%{Acct-Output-Octets}:-0}'::bigint), \
'%{Called-Station-Id}', '%{Calling-Station-Id}', '%{Service-Type}', \
'%{Framed-Protocol}', NULLIF('%{Framed-IP-Address}', '')::inet, ( NOW() - '%{%{Acct-Delay-Time}:-0}'::interval ), \
'%{Acct-Terminate-Cause}', '%{%{Acct-Delay-Time}:-0}' \
WHERE NOT EXISTS (SELECT 1 FROM upsert);"
The Start is nothing special, but the Stop, which writes the query to a file for every stop request is where the good stuff is. If you copy and paste this into your sql_log config file, it should work without any modification.
Things to note:
- When you see
'1 second'::interval * %{%{Acct-Session-Time}:-0}and feel tempted to rewrite it as'%{%{Acct-Session-Time}:-0}'::interval, DON’T! This will work 99% of the time but when the number is a big int you will get an “‘interval’ field value out of range error”. - When you’re inserting a new row for a Stop packet rather than the usual behaviour of updating an existing one, you have to calculate the AcctStartTime from the Accounting packet manually from the data supplied by the NAS. You need to be careful by casting to a bigint because the number might be too big for an integer.
- The query makes use of an SQL feature of INSERT statements, where you can INSERT rows based on the results of a query. It’s a really handy facility that I’ve used many times, particularly for populating join tables.
Conclusion
This post is deliberately slightly shorter than the others in the series as it’s more of a copy-and-paste helper for people wanting to upsert rows into the radacct database. However, I hope the explanation of CTEs and how they can be used go some way to showing the flexibility of PostgreSQL.