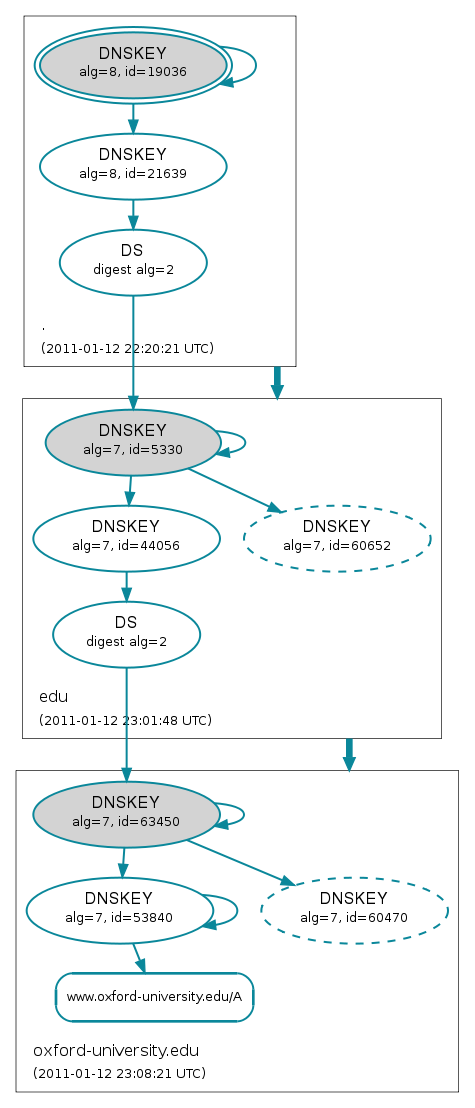
So the big news is that as of this morning www.ox.ac.uk / ox.ac.uk has AAAA records and is hence reachable via IPv6, so currently the university IPv6 presence for World IPv6 day will be:
Websites
- www.ox.ac.uk
- www.maths.ox.ac.uk (plus subsites)
- www.ashmus.ox.ac.uk / www.ashmolean.org
- Networks team webservers for IT staff tools
- blogs.it.ox.ac.uk
- oxfile.ox.ac.uk
Other services:
- irc.ox.ac.uk (relevant blog post although the service is now hosted by the Systems Development Team)
- webcache.ox.ac.uk (relevant blog post)
- ntp.oucs.ox.ac.uk (was previously ntp6.oucs.ox.ac.uk which is now CNAME’d)
The Maths Institute and the Ashmolean Museum?
Yes, both local units are taking part as IPv6 early adopters. We can’t currently offer IPv6 to all units until we’ve a working IPAM for IPv6 since we have to hand edit forward and reverse zone files to add IPv6 records currently, which isn’t scalable. The issue we’re having with the off the shelf solutions is integration with Single Sign On, specifically a lot of vendors (and indeed internal staff) don’t understand the term and confuse it with shared sign on, or a common authentication source that is passed the users credentials.
Cambridge has a similar political makeup to ourselves and a homegrown DNS management system like our own however I believe theirs is actively maintained by someone dedicated to DNS/DHCP and based on a database backend. Sadly our own is almost a decade old and uses flat files, the front end itself is about 4k lines of code the backend 3.5k, the author has retired, leaving no documentation lines in the code. Altering this code is risky and the changes needed for IPv6 support would be non trivial.
Any other issues?
Yes. There’s some changes we need to make with the way we respond to security incidents (blocking infected/compromised hosts etc) as the current mechanism is causing some CPU load on the switches, but what might initially seem a trivial problem requires to a major re-write of a backend application that manages blocks and displays the current blocked hosts to ITSS.
As of this week we’ve also discovered that the way we’re suppressing IPv6 auto configuration on networks is imperfect, in that Mac OSX hosts prior to 10.6.4 will configure IPv6 with null information. There appears to be no workaround for this on our provisioning so the options are:
- Upgrade all mac OSX hosts on the client network to 10.6.4 or above
- Don’t enable IPv6 on any network with Mac OSX hosts
- Don’t suppress IPv6 discovery on the network, meaning devices will automatically assign themselves an IPv6 address
For the moment we’re simply warning the end units that this issue exists.They can have auto discovery on or off for their network.
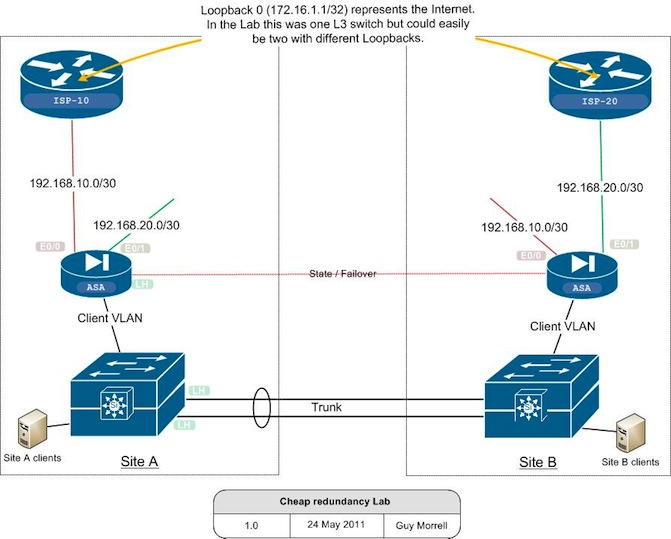
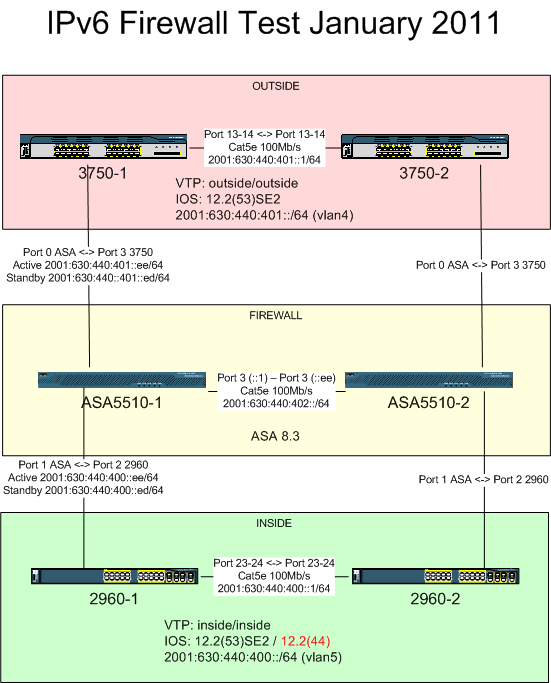
And finally there’s the university IPv6 firewall, separate to the IPv4 firewall. We want to replace the current trial system with a production failover capable system. This couple of weeks (in fact, it seems every week since February) has been incredibly busy and I didn’t get as much testing or preparation done for the production replacement as I’d like. As a result it was not surprising that in production test this morning it didn’t work and the troubleshooting was made awkward due to 101 minor issues associated with not preparing enough. I reverted it after ~5 minutes. I did set up the new solution and send traffic across it on our air gapped test network prior to this mornings work. I think the main problem was that I wanted to do more tests that we simply ran out of time for but to a lesser extent even if we had the time it’s not a perfect mirror of what the production environment is like (for example, the test network doesn’t get Cisco 6500’s for cost reasons) so there would still have been some smaller margin for unexpected error.
I’ll probably remove the AAAA’s for www.ox.ac.uk/ox.ac.uk in advance and then attempt another changeover on Tuesday morning in the ja.net at risk period depending on how much progress I can make today and Monday.
So the main site is on native IPv6 and will be staying on this after the 8th June?
Sadly not. The main website involves the participation of 5 teams. One provides (our own, based at OUCS) the core networking to the unit, one administers the virtual machine the webserver is on (NSMS), another university department administers the underlying hardware and local network, an external contractor provides the CMS that makes up the site and the final team is the Public Affairs Directorate that have political control of the site, it’s funding and what happens to it.
Despite early optimism there’s been an issue with approval for IPv6 to be enabled on the underlying local network (our own team acts in an ISP role, we don’t have political or technical control to the edge) so instead the IPv6 provision for the main site is via a reverse proxy. Essentially this is a webserver listening on Ipv6 and then making requests on the clients behalf to the main IPv4 site.
A reverse proxy? A well respected academic doing work in the IPv6 field told me that there’s little value in taking part in World IPv6 day with a reverse proxy
If I were judging a organisation commitment by their IPv6 involvement and they had used a reverse proxy then depending how proud they were about it I might indeed question their dedication since they’ve not actually made the larger changes needed for native IPv6 to their core systems.
However, from our present viewpoint I see the other argument: due to the internal problems mentioned, we had the option of either not taking part or using a reverse proxy with no native option. Taking part has advantages, specifically gathering information, getting the various teams experienced in IPv6 configuration and gaining political support and understanding among management that future work is needed (we are not all well respected academics, some internal people just don’t believe IPv6 is needed and assume it is simply the cause of issues).
So in summary, I agree with the viewpoint however I think we gain value in any IPv6 progress that can be made in the university, no matter how small.
What might a local IT support office be doing at their unit?
- For the long term you should take a look at the basic IPv6 preparation advice if you haven’t already.
- For desktop support and other more immediate problems, take a look at the arin wiki information.