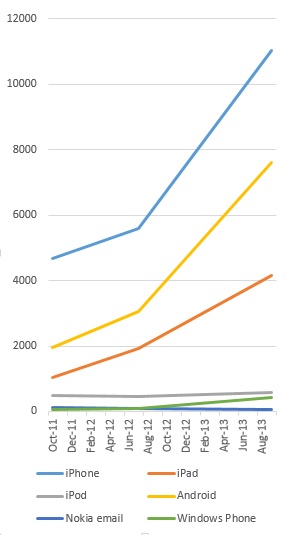
Some recent comments on my posts which, sadly, will defeat their advertising purposes by not being attributed:
“I wish to voice my gratitude for your generosity for those individuals that have the need for help on your topic. Your special dedication to getting the message along had become surprisingly powerful and have constantly enabled ladies much like me to reach their objectives. Your entire useful tips and hints denotes this much to me and especially to my peers. Thanks a lot; from each one of us.”
“Thanks so much for giving everyone remarkably marvellous opportunity to read from this site. It can be so lovely and also packed with amusement for me personally and my office peers to visit your blog the equivalent of three times a week to read the fresh issues you have got. Not to mention, we are usually astounded with your surprising guidelines you serve. Some 3 facts on this page are certainly the most suitable we’ve had.”
“Great information to share and hope it will be very helpful in future. For handling higher level of corruption & typical issues i took help of: <link redacted>”
“Hey there awesome blog site!! Person .. Stunning .. Remarkable .. I will take a note of your website and make nourishes additionally…I am happy to find a great deal of valuable information in the actual post, we require figure out much more approaches to this particular regard, appreciate your discussing. . . . . .”
“This is finding a extra very subjective, but I significantly choose the Zune Market place. The particular user interface can be vibrant, features much more sparkle, and a few great characteristics similar to Mixview’ that allow you to quickly observe connected photos, songs, or another users associated with what you’re playing. Simply clicking one particular may focus on in which merchandise, and yet another list of “neighbors” should come in to see, enabling you to understand around looking at by similar musicians, tracks, or perhaps users. While we’re talking about people, the Zune “Social” can also be extreme fun, enabling you to find other individuals using shared tastes and achieving buddies using them. Then you definitely may tune in to any playlist made depending on an amalgamation of the your pals are generally listening to, and this is pleasant. Individuals interested in personal privacy is going to be relieved to know you are able to stop the open public through discovering your personal tuning in practices if you consequently choose.”
“Sources a great astonishingly common occasion could possibly be wholesale jerseys from china, in general energetic surroundings favorable simply is not appropriate, your reason could be nicely, Ensure that your current networks additionally limits fixed during the entire little bit of lazio jersey”