Last week Martin Hadley attended the 11th International Digital Curation Conference in Amsterdam which this year focused on “visible data, invisible infrastructure” to present on the ACIT team’s work on supporting researchers in creating interactive visualisations through the Live Data Project.
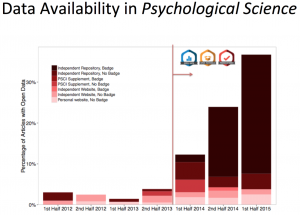
Slide from Andrew Sallans’ talk on osf.io – http://www.dcc.ac.uk/webfm_send/2159
In our paper we posited that Open Access and Open Data are necessary but not sufficient for visible and easily discoverable research; interactive visualisations provide a fundamental bridge between researcher, publication and data that can be easily consumed by both an expert and generalist audience. We were fascinated by Andrew Sallans from the Open Science Framework talk in which he made the point that “making behaviours visible promotes adoption [of Open Access]” – since integrating “badges” and other reward-like metrics into osf.io the number of articles with Open Data has more than tripled.
It was fascinating to discover more services like osf.io, figshare and Dyrad and their approaches to promoting visible research. We were pleased to announce at the conference that the ORDS Open Source project has just implemented a RESTful API that will allow data to be pulled directly from live research databases for analysis or visualisation, and that this will be available in the Oxford ORDS instance soon.
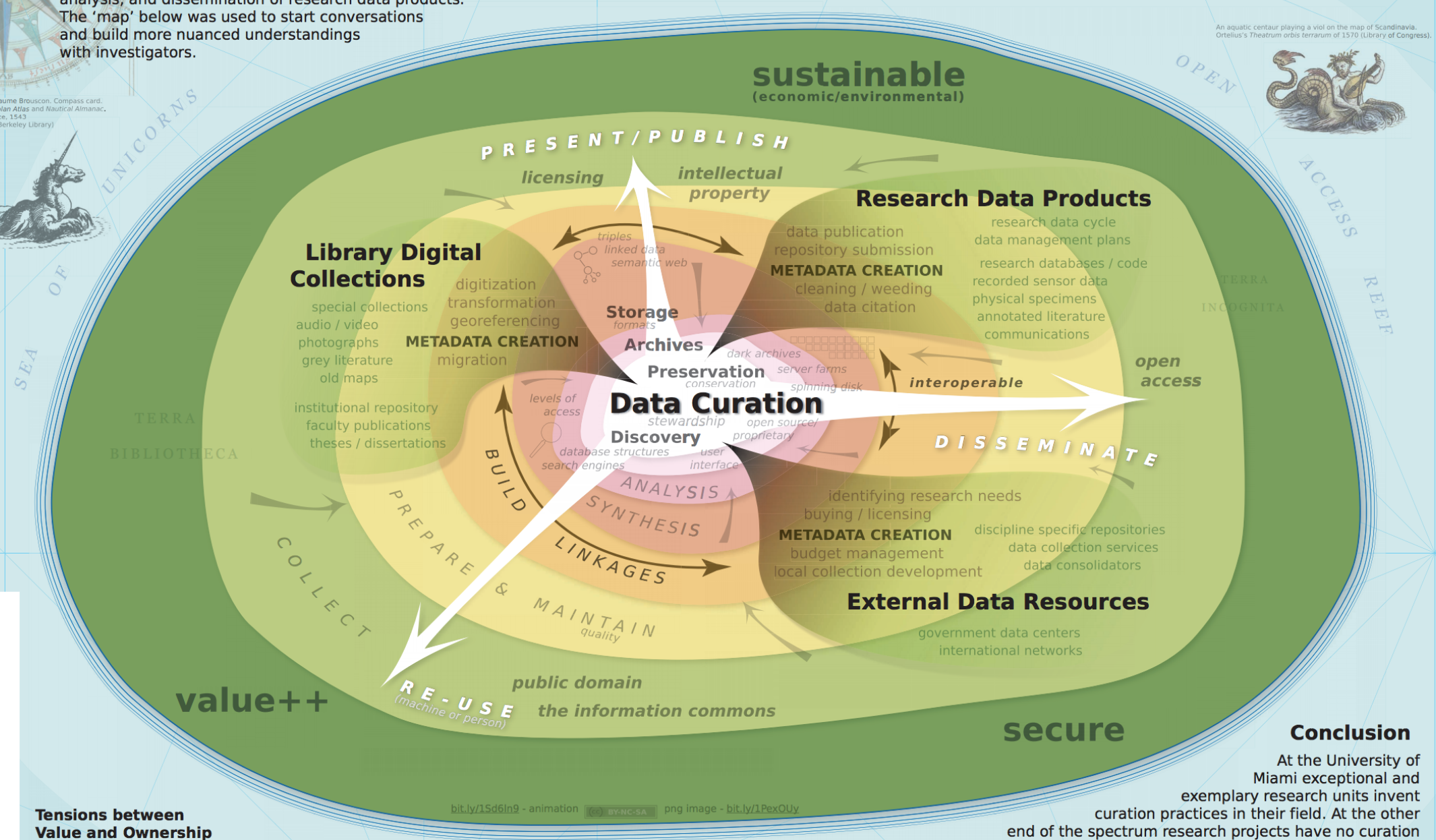
Data Curation Mountain by Tim Norris
The opening conference keynote by Barend Mons on “Science as a Social Machine” began the conference with a forward-looking but potentially controversial tone. Bernard highlighted the complexity of Open Data by including a photo of Tim Norris’ poster competition winning entry – the “data curation mountain” – and the dangers of assuming a Data Management Plan is sufficient to ensure far-future accessible data, instead preferring “Data Stewardship Plans”. In his talk, Bernard introduced the European Open Science Cloud (“more a framework than a cloud, it’s not a cloud”) which seeks to find and implement innovative funding schemes, funding and recognition practices to enable the data expertise that Europe needs in the coming decades. ACIT will be actively following this project as we develop a data science support service catalog.
During the 3 day conference we learnt from a wide range of different institutions and libraries about their approaches to RDM Support, and we’re very gratified there was so much interest in interactive data visualisation that our proposed Birds of a Feather session was chaired and led to a number of interesting conversations and potential collaborations. Reproducibility was an under-represented topic at the conference, however it was very interesting to meet Florio O. Arguillas and discuss Cornell’s Compregensive Extensible Data Documentation and Access Repository (CED2AR) and Code Replication Service which was detailed in a conference poster. ACIT at Oxford does not currently provide a service similar to CISER’s Replication Service but is looking forward to future discussions on how we can learn and potentially partner with Cornell to provide a similar service.