So, during this summer, I had an unique opportunity – to be a part of the team of ninjas sysadmins at the Systems Development and Support Section at the University of Oxford as part of the IT Services Internship Programme. I was a part of the Infrastructure and Hosting team (IAH), which along with the Identity and Access Mangement team (IAM) comprise the Systems Development and Support Section. My work was supervised by Dominic Hargreaves and Dave Stewart of IAH. (That’s it, I promise there will be no more acronyms!)
Over a period of two months, I completed a series of miscellaneous tasks, mostly in the area of increasing efficiency in a few of the tools and writing network visualisation tools to get an overview of the topology and dependencies among the servers that the IAH team have to support and maintain.
Settling in: solving papercut bugs
The first fortnight was spent in getting accustomed to the daily tools used by the team — such as request-tracker, the ticketing system; and getting acquainted with the wiki, which serves as a knowledge base for common procedures. I fixed a few tickets, mostly trivial changes such as changing email addresses from help@oucs.ox.ac.uk to help@it.ox.ac.uk reflecting the change in name of the department in 2012. I also updated the documentation, adding manual pages for tools, like adding short options to a local build tool.
I also finished and deployed a website which reports on the success/failure/last updated status of the mirrors. This utility can be seen at http://mirror.ox.ac.uk/status.
Making bacman2 faster
bacman2 is the homegrown backup utility used by the IAH team to manage backups for the servers under their administrative control. It can perform rsync based filesystem backups, as well as database backups, which are done by various submodules of bacman2.
Configuration of bacman2 is done using YAML files. YAML is a human-readable format which is terser than XML and easier to read than JSON while being compatible with JSON (YAML is effectively a superset of JSON).
However the archives list of bacman2 was also kept in YAML. As the Perl YAML module is not very efficient at loading such a large YAML file (containing 300k records or more), this would cause frequent lockups as the bacman2 process blocked on updating the YAML file.
The solution was to use a proper database for this. Since the archives YAML file was not replicated and was local to only one system, it made sense to use a lightweight file-based database system like SQLite, which also has good bindings for Perl. The archives list was migrated to SQLite without any data loss.
The migration to SQLite solved the frequent locking problems and was much faster. Addition of new backups to the archive list which previously took upto a minute because of the requirement to parse the entire YAML file into memory and write it out to disk, is now instantaneous.
Network topology: dandelion
The last, and in my opinion most interesting part of the internship was developing a network topology diagram of the network of machines managed by the team. At the moment of writing there are 152 systems connected to various switches. Understanding and visualising the connectivity of these systems is critical to swift identification and localisation of any emergent problems.
An associated problem is that of host or server startup order. The various servers run by sysdev, are associated with various services that the University needs. The services are categorised by tiers, with Tier 1 being the highest priority services such as the central authentication system, with Tier 3 and 4 being the lowest priority systems.
In the event of a total or partial shutdown of the servers, it is important to know the order in which the servers should be started as some servers provide services that are depended on by other servers.
Both these tools were combined into one tool which gathers data from various sources like the configuration repository generated by the rb3 tool (the configuration management tool used and developed in-house at Oxford, available as open source) and the Cisco switch configurations and generates graphs using D3.js. The name dandelion came about from the remark by a member of the team that the network topology graph looked very much like one. The graphs allow searching for hosts and showing their properties.
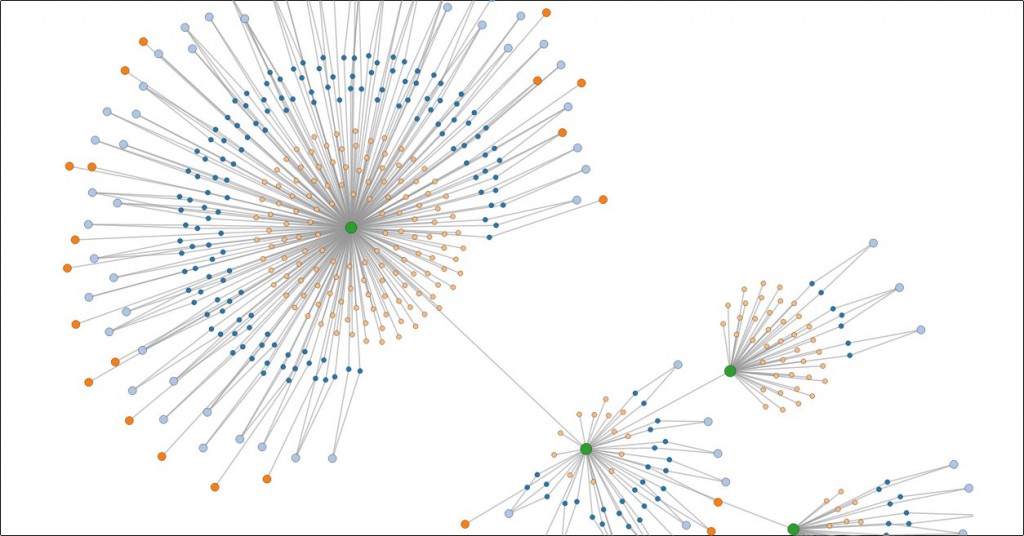
I wrote the dandelion utility as a module so that it could be reused for similar tools, and some example tools were written which can report on, for example, the Debian versions of the various systems, searching servers which have particular properties, or reporting on the various services that a particular server runs, and its relationship with the other servers on the network.
Future Work
Further work can always be done in the area of automated configuration management and visualisation, possibly by applying machine learning techniques to the configuration repository. In the last week of the internship, I was working on a similarity tool, using the dandelion framework, which gives a similarity weight between two servers on the network, based on how many properties they have in common (after removing the properties common to most systems). Such a similarity weight would identify clusters of servers performing a similar task and could be later used to show a graph of such clusterings, or be part of an utility which monitors resilience of the network (for example, it could offer suggestions about moving servers performing similar tasks into geographically more distributed locations, to reduce single points of failure).
Acknowledgements
I would like to thank Dominic Hargreaves and Dave Stewart for their excellent guidance throughout the internship. I would also like to thank Peter Grandi and Kristian Kocher, and the members of the adjoining Identity and Access Management (IAM) team for the many excellent conversations we had over beer and burritos :)
