This is the first post in a series discussing some of the finer details of the networking setup for the new eduroam infrastructure that went into production last month.
In this post, I will be covering the IP routing setup of the new networking infrastructure. This uses static routing & Virtual Routing & Forwarding instances (VRF) to get traffic from clients using the eduroam service out on to the Internet. Following on from this, I’ll explain the associated failover setup we opted for which uses the IOS ‘object-state tracking’ feature in a somewhat clever way for our active/standby setup.
What I won’t be covering here is how the traffic traverses the university backbone (from the FroDos) and is aggregated at a nominated egress (C) router within the backbone. This is because the mechanism for achieving this hasn’t actually changed much. It still uses the cleverness of the ‘Location Independent Network’ (LIN) system. I will mention briefly though that this makes use of VRFs, Multi-Protocol Label Switching (MPLS) and Multi-Protocol extensions to the Border Gateway Protocol (MP-BGP) to achieve this task. This allows us to provide LIN services (of which eduroam is one service) to many buildings around the collegiate university in a scalable way, whilst isolating these networks from others on the backbone.
Also omitted from this post are the details on how traffic from the Internet reaches our eduroam clients. Again, this is achieved in much the same way as before, using a combination of an advertising statement in our BGP configuration and some light static routing at the border for the new external eduroam IP range to get traffic to the new infrastructure.
So what are we working with?
We procured two Cisco Catalyst 4500-X switches which run the IOS-XE operating system. For those not familiar with this platform, these are all SFP/SFP+ switches in a 1U fixed-configuration form-factor. As well as delivering the base L2/L3 features you’d normally expect from a switch, this platform also delivers some other cool features you might perhaps expect to find in a more advanced chassis-based form factor (at least in Cisco’s offerings anyway).
Specifically in the context of the new eduroam infrastructure, we’re using the Virtual Switching System (VSS) to pair these switches up to act as one logical router and also microflow policing for User Based Rate Limiting (UBRL). The latter of these features will be discussed at length in a later post. There are of course other features available within this platform which are noteworthy but I won’t be discussing them here.
Running VSS in any scenario has some obvious benefits, not least of which negating the need for any First-Hop Redundancy Protocol (FHRP) or Spanning-Tree Protocol (STP). It also allows us to use Multi-chassis EtherChannels (MECs) for our infrastructure interconnects. In non-Cisco speak, these are link aggregations that consist of member ports that each connect to a different 4500-X switch in our VSS pair. For more information on the L1/L2 side of things, please see my previous post ‘Building the eduroam networking infrastructure’. All MECs have been configured in routed (no switchport) mode rather than in switching (switchport) mode. This makes the configuration far simpler in my opinion.
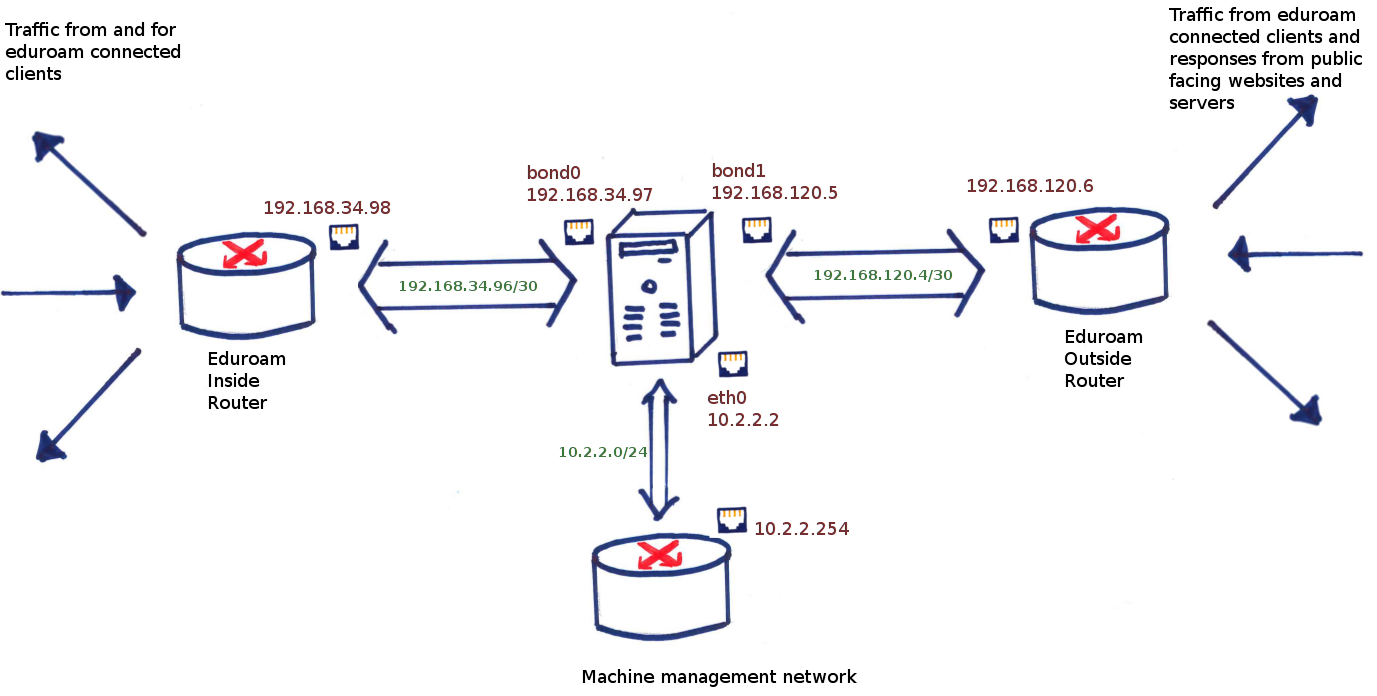
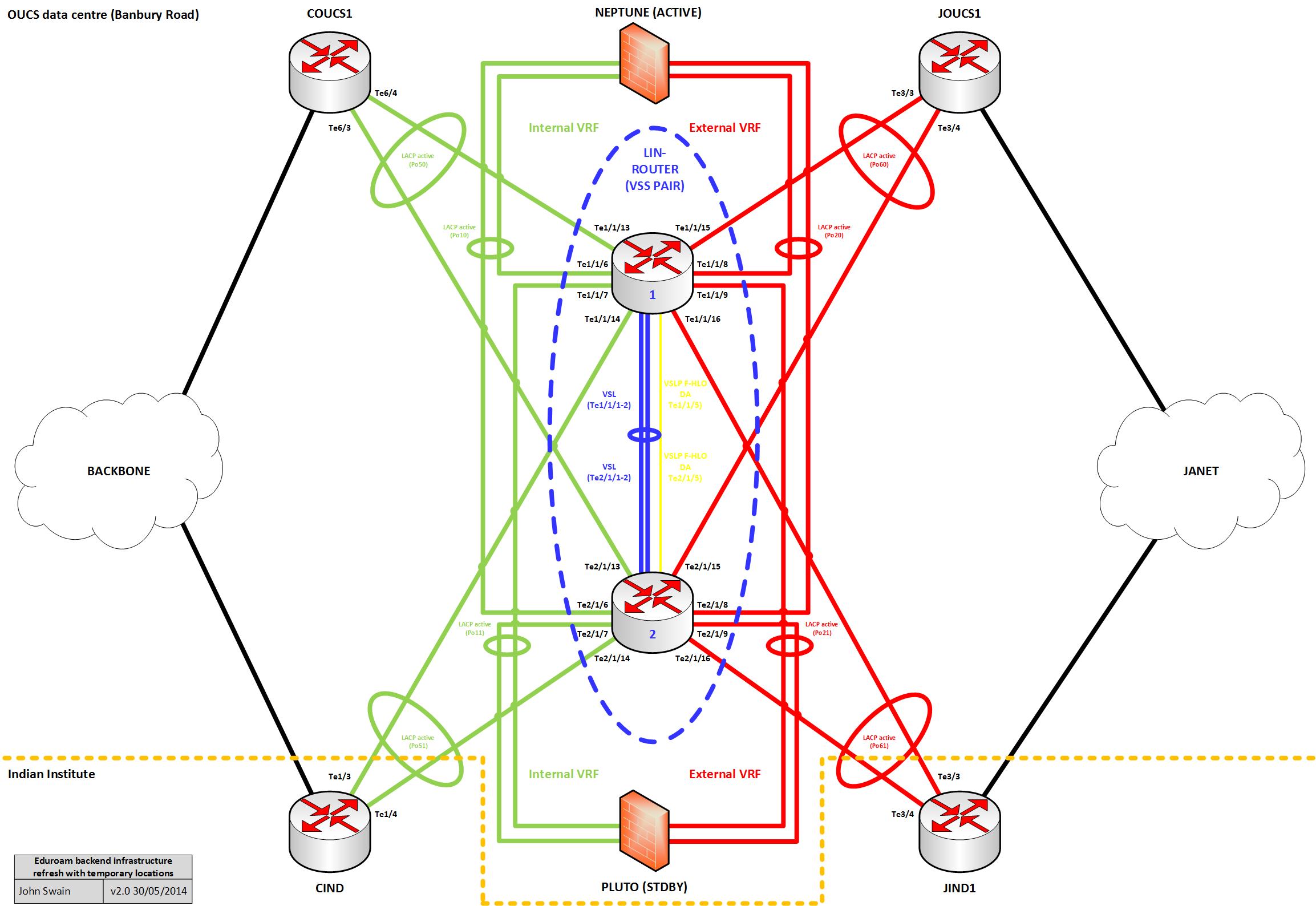
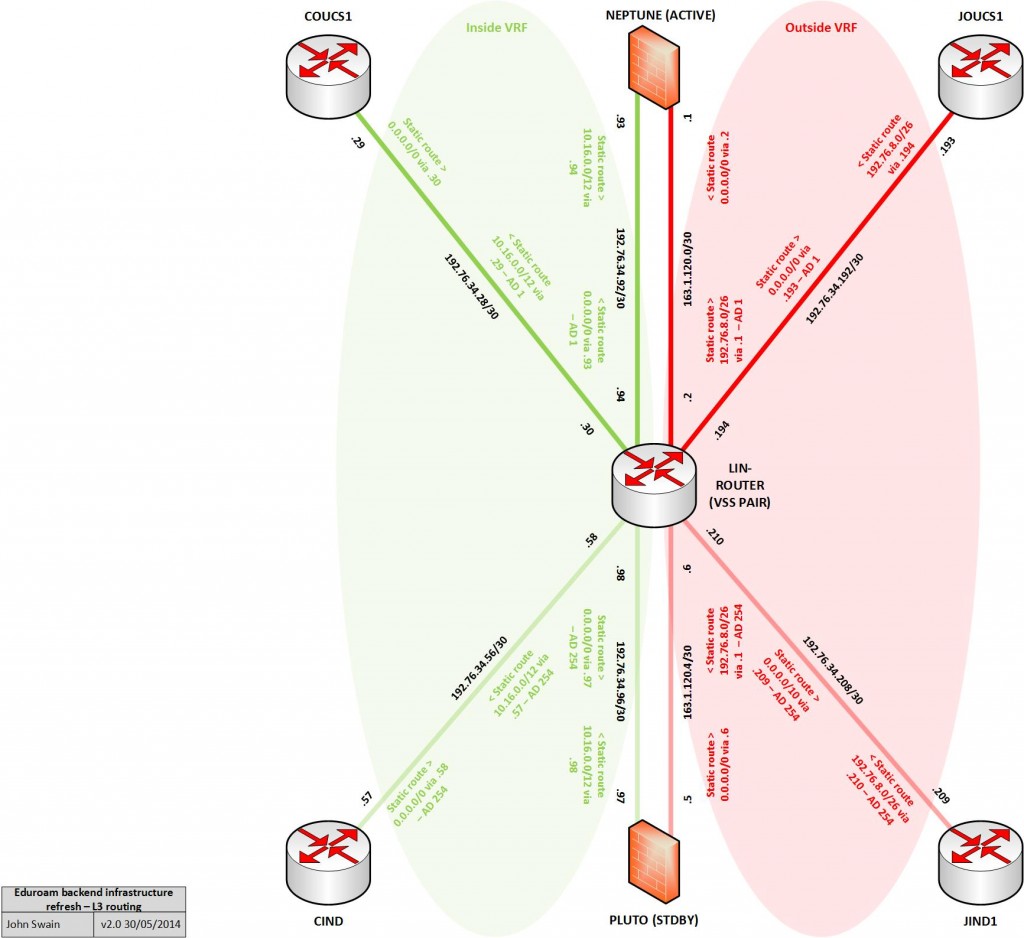
So with all this in mind, the diagram below illustrates how this looks from a logical point-of-view including some IP addressing we defined for the routed links in our new infrastructure:
Considering & applying the routing basics
OK, so with our network foundations built, we needed to configure the routing to get everything talking nicely.
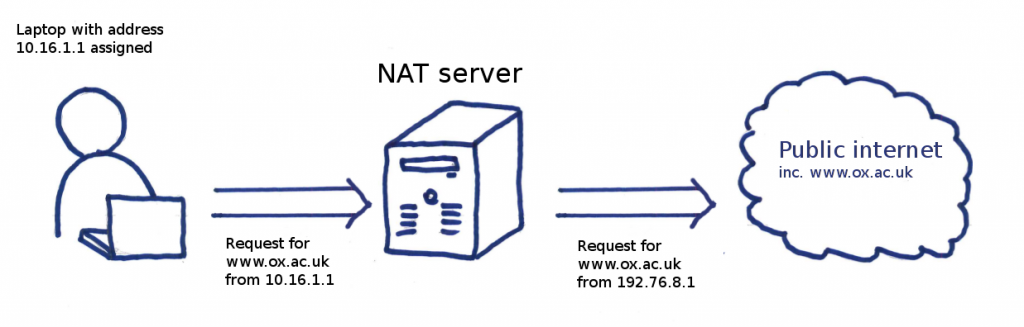
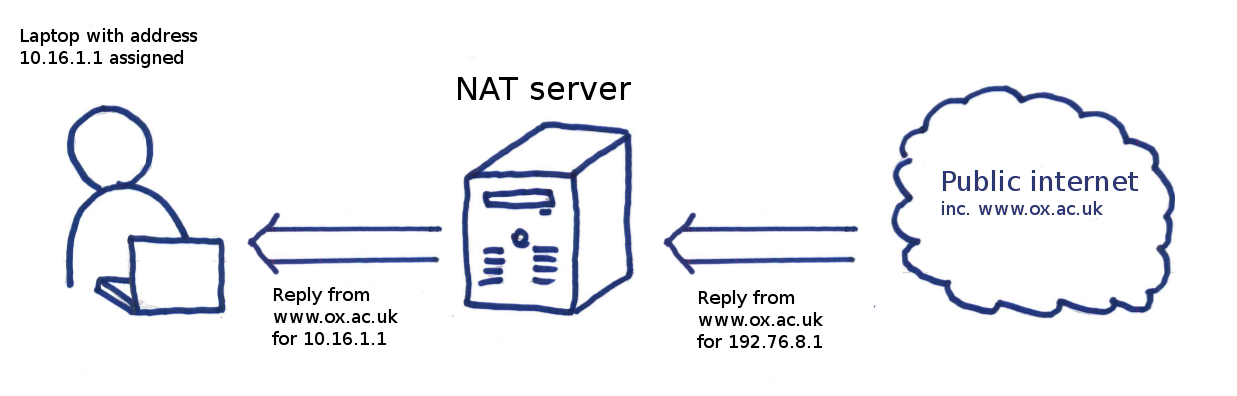
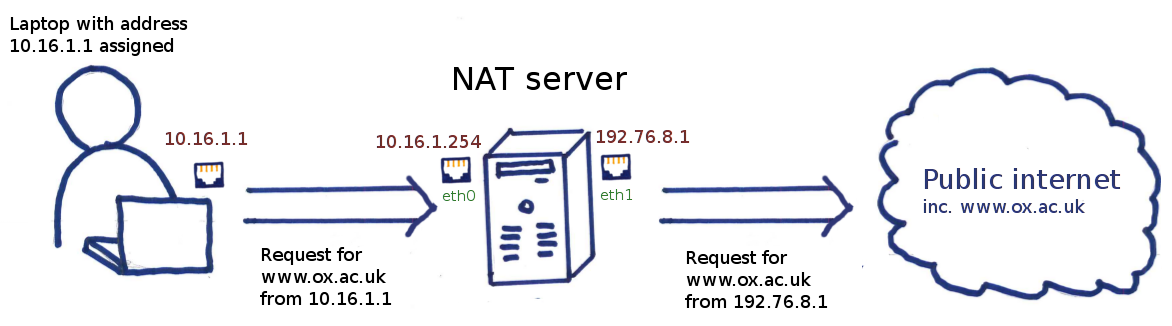
Before I went gung ho configuring boxes, I thought it would be best to stand back and have a think about our general requirements for the routing configuration. At this point, it is noteworthy to mention that all Network Address Translation (NAT) in the design is handled externally by the Linux hosts in our infrastructure (my colleague Christopher has written an excellent post covering the finer points of NAT on Linux for those interested).
I summarised our requirements for the routing configuration as follows:
- Traffic from clients egressing the university backbone (addressed within the internal eduroam LIN service IP range 10.16.0.0/12) should have one default route through the currently active Linux host firewall. This is pre NAT of course and the routing for replies back to the clients should also be configured;
- Traffic from clients that makes it through the Linux host firewall egressing towards the Internet (NAT’d to addresses within the external eduroam IP range 192.76.8.0/26) should have one default route through the currently active border router. Once again, the routing for replies back to the clients should also be configured;
- Routing via direct paths (bypassing our Linux firewalls) should not be allowed;
- Ideally, the routing of management traffic should be kept isolated from normal data traffic.
With these requirements in mind, I started to consider technical options.
First of all, we decided to meet requirements 3 & 4 using VRFs. More specifically, what we would use is defined as a VRF ‘lite’ configuration – that is, separate routing table instances but without the MPLS/MP-BGP extensions. At this point, I would highlight that for the 4500-X platform, the creation of additional VRFs required the ‘Enterprise Services’ licence to be purchased and applied to each switch. This may not be the case with other platforms so if it’s a feature you ever intend to use, do ensure you check the licensing level required – of course I’m sure everyone checks these things first right?
To fulfil requirement 4, we would make use of the stock ‘mgmtVrf’ VRF built-in to many Cisco platforms (including the 4500-X) for the purpose of Out-Of-Band (OOB) management via a dedicated management port. This port is by default locked to this VRF anyway (so you can’t change its assignment even if you wanted to). We were forced down this route because there are no other built-in baseT ethernet ports on these switches to connect to our local OOB network – OK, we could have installed a copper gigabit SFP transceiver in one of the front-facing ports, but that would have been a waste considering the presence of a dedicated management port! I’ll avoid further discussion of this here as it’s outside the scope of this post. However I do intend to cover this topic in a later post as setting this up really wasn’t as easy as it should have been in my honest opinion.
So, I started with the following configuration to break up the infrastructure generally into two ‘zones’. One VRF for an ‘inside’ zone (university internal side) and another for an ‘outside’ zone (the Internet facing side):
vrf definition inside
address-family ipv4
exit-address-family
exit
vrf definition outside
address-family ipv4
exit-address-family
exit
Note the syntax to create VRFs on IOS-XE is quite different to that of it’s IOS counterparts. In IOS-XE It is necessary to define address family configurations for each routed protocol you wish to operate (in a similar way to how you would do with a BGP configuration for example). In this scenario, we are only running unicast IPv4 (for now at least) so that’s what was configured. With our new VRFs established, it was then necessary to assign the appropriate interfaces to each VRF and give them some IP addressing. The example below depicts this process for two example interfaces – I simply rinsed and repeated as necessary for the others in the topology:
interface Port-channel50
description to COUCS1
no switchport
vrf forwarding inside
ip address 192.76.34.30 255.255.255.252
no shut
exit
interface Port-channel60
description to JOUCS1
no switchport
vrf forwarding outside
ip address 192.76.34.194 255.255.255.252
no shut
exit
With this completed for all interfaces, I verified the routing tables had been populated like so:
#Global table:
lin-router#sh ip route
<snip>
Gateway of last resort is not set
‘Inside’ VRF table:
lin-router#sh ip route vrf inside
<snip>
Gateway of last resort is not set
192.76.34.0/24 is variably subnetted, 8 subnets, 2 masks
C 192.76.34.28/30 is directly connected, Port-channel50
L 192.76.34.30/32 is directly connected, Port-channel50
C 192.76.34.56/30 is directly connected, Port-channel51
L 192.76.34.58/32 is directly connected, Port-channel51
C 192.76.34.92/30 is directly connected, Port-channel10
L 192.76.34.94/32 is directly connected, Port-channel10
C 192.76.34.96/30 is directly connected, Port-channel11
L 192.76.34.98/32 is directly connected, Port-channel11
‘Outside’ VRF table
lin-router#sh ip route vrf outside
<snip>
Gateway of last resort is not set
163.1.0.0/16 is variably subnetted, 4 subnets, 2 masks
C 163.1.120.0/30 is directly connected, Port-channel20
L 163.1.120.2/32 is directly connected, Port-channel20
C 163.1.120.4/30 is directly connected, Port-channel21
L 163.1.120.6/32 is directly connected, Port-channel21
192.76.34.0/24 is variably subnetted, 4 subnets, 2 masks
C 192.76.34.192/30 is directly connected, Port-channel60
L 192.76.34.194/32 is directly connected, Port-channel60
C 192.76.34.208/30 is directly connected, Port-channel61
L 192.76.34.210/32 is directly connected, Port-channel61
This output confirms that I addressed the interfaces properly, assigned them to the correct VRFs and that they were operational (ie capable of forwarding). It also confirmed the presence of no routes in the global routing table which is what we wanted – isolation!
At this point though, it would still be possible to ‘leak’ routes between VRFs so to eliminate this concern, I applied the following command:
no ip route static inter-vrf
So we now have some routing-capable interfaces isolated within our defined VRFs. Next, we need to make things talk to each other!
Considering static routing vs dynamic routing
We needed a routing configuration to get some end-to-end connectivity between our internal eduroam clients and the outside world. This basically boiled down to one major question and fundamental design decision – ‘Shall I define static routes or use a routing protocol to learn them?’ There are always pros and cons to either choice in my honest opinion.
Why? Well static routing is great in its simplicity and for the fact it doesn’t suck up valuable resources on networking platforms. It does however have the potential for laborious administrative overhead – especially if used excessively! In other words, it doesn’t scale well in some large deployments.
Dynamic routing via an Interior Gateway Protocol (IGP) can be a great choice depending on the situation and which one you choose. They reduce the need for manual administrative overhead when changes occur but this does come at a price. Routing protocols consume resources such as CPU cycles and require administrators to have a sound knowledge of their internal mechanisms and their intricacies when things go wrong. This can get interesting (or painful) depending on the problem scenario!
So I would suggest this decision comes to picking the ‘right tool for the right job’. As a general rule of thumb, I tend to work on the basis that large environments with many routes that change frequently probably need an IGP configuration. Everything else can usually be done with static routing.
Some history
Previously with the old infrastructure, we made use of the Routing Information Protocol version 2 (RIPv2) IGP to learn and propagate routes. I believe this was a design decision based on two main factors – I leave room for being wrong here though as it was admittedly before my time. I summarised these as:
- The need for two physical switches performing the routing for internal and external zones – This in itself would have mandated a larger number of static routes so an IGP configuration probably seemed like a more logical choice at the time;
- RIPv2 was the only IGP available using the IP base license on the Catalyst 3560 switches.
There could have been other reasons too of course. RIPv2 for those that don’t know is a ‘distance-vector’ routing protocol that uses ‘hop count’ as it’s metric.
RIPv2 communicated routes between the separate internal and external switches in the old topology through the active Linux firewall host. What this meant in production was that a loss of a link or the Linux host running the firewall resulted in a re-convergence of the routed topology to use the standby path. The convergence process when using RIPv2 is quite slow really and to initiate a failover manually (say you wanted to pull the Linux host offline to perform some maintenance for example) meant re-configuring an ‘offset list’ to manipulate the hop count of the routes to reflect your desired topology. Granted this all worked, but it felt a little clunky at times!
Static routing simplicity
For the new infrastructure, we don’t have two switches performing the routing (there are two switches but these are logically arranged as one with VSS). Instead we have logical separation with VRFs which equates to having two logical routers. With this design, there is no requirement for direct inter-VRF communication – instead our firewalls provide inter-VRF communication as required. This, coupled with the considerations above, ultimately led to a decision to use a static routing configuration over one based on dynamic routing with an IGP.
To elaborate further, the routing configuration in this new design really only requires two routes per VRF per path (ignoring the mgmtVrf). For the active path for example, these are:
#From eduroam clients to Linux firewall host:
ip route vrf inside 0.0.0.0 0.0.0.0 192.76.34.93
#From Linux firewall host to eduroam clients:
ip route vrf inside 10.16.0.0 255.240.0.0 192.76.34.29
#From eduroam clients (post-NAT) to the Internet
ip route vrf outside 0.0.0.0 0.0.0.0 192.76.34.193
From the Internet to eduroam clients (post-NAT)
ip route vrf outside 192.76.8.0 255.255.255.0 163.1.120.1
So this is a very simple and lightweight static routing configuration really. OK, so it does get a little larger and more complicated with the failover mechanism and the standby path routes included, but not by much as you’ll see shortly. In total there are only ever likely to be a handful of routes in this configuration that are unlikely to change very frequently so the administrative overhead is negligible.
How shall we handle failures?
At this point, assuming we’d configured the routing as described and had added our standby routes in exactly the same fashion, what we’d have actually ended up with is an active/active type setup – at least from the networking point-of-view. This would have resulted in traffic through our infrastructure being load-balanced across all available routes via both firewall hosts.
Configuring the additional routes in this way might have been OK had these general caveats not been true of our firewall/NAT setup:
- The NAT rules on both firewall hosts translate traffic sourced from internal (RFC1918) IP addresses into the same external IP address range;
- The firewall hosts do not work together to keep track of the state of their NAT translation tables.
So at this point, my work clearly wasn’t done yet. In our scenario we were most certainly going to carry on with an active/standby setup (at least in the short-term).
I reached the conclusion that what was needed was a way to track the state of the active path to make sure that if a full or partial path failure occurred, a failover mechanism would ensure all traffic would use the secondary path instead.
Standby path routes
When I added these routes, I in fact configured them slightly differently. Specifically, I configured them with a higher Administrative Distance (AD) value.
To explain briefly, AD is assigned based on the source of the route. For instance, we can consider two sources in this context to be routes that have been statically configured, or ones that have been learned via an IGP for example. There are some default values IOS & IOS-XE assigns to each route source. AD only comes into play if you have more than one exactly matching candidate route to a destination (of the same prefix length) offered to the routing table from different sources. The one with the lowest AD in this situation wins and is then installed in the routing table.
You can view the AD value currently assigned to a route by interrogating the routing table. For example, let’s look at the static routes in the inside VRF routing table:
lin-router#sh ip route vrf inside static
<snip>
Gateway of last resort is 192.76.34.93 to network 0.0.0.0
S* 0.0.0.0/0 [1/0] via 192.76.34.93
10.0.0.0/12 is subnetted, 1 subnets
S 10.16.0.0 [1/0] via 192.76.34.29
I’ve highlighted the AD values in bold in the output for illustration purposes. You can see the default AD value of ‘1’ is applied to these routes. The second value is the ‘metric’ of the route, in the case of the two routes shown here, the next-hop is connected to the router so this is ‘0’.
So in the case of our standby routes, I assigned an AD value of ‘254’ to the standby routes. This was achieved using the following commands:
#From eduroam clients to Linux firewall host:
ip route vrf inside 0.0.0.0 0.0.0.0 192.76.34.97 254
#From Linux firewall host to eduroam clients:
ip route vrf inside 10.16.0.0 255.240.0.0 192.76.34.57 254
#From eduroam clients (post-NAT) to the Internet
ip route vrf outside 0.0.0.0 0.0.0.0 192.76.34.209 254
From the Internet to eduroam clients (post-NAT)
ip route vrf outside 192.76.8.0 255.255.255.0 163.1.120.5 254
You may see the creation of static routes with an artificially high AD value sometimes referred to as creating ‘floating’ routes. They can be considered to float because they will never be installed in the routing table (or sink if you will) provided that matching routes with a better (lower) AD value have already been installed. So our standby path routes will now be offered to the routing table in the event the active ones disappear for any reason.
At this point, I noted that we could still end up in a situation where a new path made up of a hybrid of both active and standby links could be selected. In our scenario, I feared this could result in undesired asymmetric routing and make traffic paths harder to predict. What I really wanted was an easily predictable path every time regardless of where a failure occurred or the nature of such a failure.
Introducing IOS ‘object-state tracking’
The object-state tracking feature does pretty much what the name implies. You configure a tracking object to check the state of something – be it an interface’s line protocol status or a static route’s next hop reachability for instance. The two possible states can either be ‘up’ or ‘down’ and depending on the configuration you apply and a change in state can trigger some form of action.
What to track and how to track it
It was clear that what was needed was a way to track each of our directly connected links making up our active path. To re-cap, these are:
‘Inside VRF’
- C 192.76.34.28/30 is directly connected, Port-channel50
- C 192.76.34.92/30 is directly connected, Port-channel10
‘Outside VRF’
- C 163.1.120.0/30 is directly connected, Port-channel20
- C 192.76.34.192/30 is directly connected, Port-channel60
To start with, I decided to map these to separate tracking-objects using the following configuration:
track 2 ip route 192.76.34.92 255.255.255.252 reachability
ip vrf inside
delay down 2 up 2
track 3 ip route 192.76.34.28 255.255.255.252 reachability
ip vrf inside
delay down 2 up 2
track 4 ip route 163.1.120.0 255.255.255.252 reachability
ip vrf outside
delay down 2 up 2
track 5 ip route 192.76.34.192 255.255.255.252 reachability
ip vrf outside
delay down 2 up 2
One potential gotcha to watch for when configuring tracking objects for routes/interfaces assigned within VRFs is that it is also necessary to define the VRF in the object itself. If you don’t, you’ll likely find that your object will never reach an up state (because the entity being tracked doesn’t exist as far as the global routing table is concerned). I admit, I got caught out by this the first time around!
Note that an alternative strategy I could have chosen would have been to monitor the line protocol of the interfaces involved. There is a good reason I didn’t configure the objects this way. This is basically because it’s inherently possible for the line protocol of the interfaces to stay up but there be other issues causing an IP to be unreachable. I therefore figured tracking reachability would be the safest and most reliable option for our scenario.
Also delay up/down values (in seconds) have been defined. These just add a delay of 2 seconds whenever the state of one of the objects changes from up->down or down->up. I’ll explain this further in the context of our failover mechanism shortly.
Tying the tracking configuration together with the other elements
At this point, the configuration gets a bit more interesting (at least in my view). What I wasn’t originally aware of is that it’s possible to in effect ‘nest’ a list of tracking objects within another tracking object. Therefore to meet our requirements, I created another tracking object (the ‘parent’) to track the objects I created earlier (the ‘daughters’):
track 1 list boolean and
object 2
object 3
object 4
object 5
delay down 2 up 2
This configuration allows us to track the state of many daughter objects. If one of these ever reaches the ‘down’ state, this also causes the parent tracking object to follow suit using the ‘boolean and’ logic parameter.
With the object-tracking configuration completed, I proceeded to amend the static route configuration for the active path to make use of the parent tracking object:
#Removing previous static routes for active path:
no ip route vrf inside 0.0.0.0 0.0.0.0 192.76.34.93
no ip route vrf inside 10.16.0.0 255.240.0.0 192.76.34.29
no ip route vrf outside 0.0.0.0 0.0.0.0 192.76.34.193
no ip route vrf outside 192.76.8.0 255.255.255.0 163.1.120.1
#Re-adding static routes with reference to parent tracking object:
ip route vrf inside 0.0.0.0 0.0.0.0 192.76.34.93 track 1
ip route vrf inside 10.16.0.0 255.240.0.0 192.76.34.29 track 1
ip route vrf outside 0.0.0.0 0.0.0.0 192.76.34.193 track 1
ip route vrf outside 192.76.8.0 255.255.255.0 163.1.120.1 track 1
What this gives us is a mechanism that will remove *all* the active path static routes if any one, many or all of the directly connected active links fails. The cumulative delay between an object state change (and therefore when any routing table change will occur) in our scenario should be:
daughter_object_delay + parent_object delay = total delay time.
So that’s:
2 + 2 = 4 seconds of total delay time.
You might be wondering why I configured these particular delay values on the objects, or even why I bothered delay times at all. Well, I did so in an effort to guard against the possibility of the state of an object rapidly transitioning.
Why could this be an issue? Well in our scenario here, it could result in routing table ‘churn’ (routes rapidly being installed and withdrawn from the routing table) which in-turn could have a negative impact on the performance of the switches. Frankly, I don’t see this being a likely occurrence and even if it did, I’m not sure it would be enough to drastically impact the performance of the switches (especially in light of their relatively high hardware specification) but the rapid state transitioning could be possible, say for instance, if a link were to flap (go up and down rapidly) because of an odd interface or transceiver fault. It’s probably best to think of these values and their configuration as a kind of insurance policy.
Generally, I think the resulting failover time of approximately 5 seconds is acceptable in this scenario and is certainly going to be an improvement over what we would have experienced with the old infrastructure using RIPv2.
Does it work?
Yes it does and to prove the point, I’ll demonstrate this using an identical configuration I ‘labbed up earlier’ in our development environment. Rest assured, it’s been tested in our production environment too and we’re confident it works in exactly the same way as what’s shown below.
Here’s some output from the ‘show track’ command illustrating everything in a working happy state:
Rack1SW3#show track
Track 1
List boolean and
Boolean AND is Up
112 changes, last change 2w5d
object 2 Up
object 3 Up
object 4 Up
object 5 Up
Delay up 2 secs, down 2 secs
Tracked by:
STATIC-IP-ROUTINGTrack-list 0
Track 2
IP route 192.76.34.92 255.255.255.252 reachability
Reachability is Up (connected)
106 changes, last change 2w5d
Delay up 2 secs, down 2 secs
VPN Routing/Forwarding table "inside"
First-hop interface is Port-channel10
Track 3
IP route 192.76.34.28 255.255.255.252 reachability
Reachability is Up (connected)
2 changes, last change 12w0d
Delay up 2 secs, down 2 secs
VPN Routing/Forwarding table "inside"
First-hop interface is Port-channel48
Track 4
IP route 163.1.120.0 255.255.255.252 reachability
Reachability is Up (connected)
96 changes, last change 2w5d
Delay up 2 secs, down 2 secs
VPN Routing/Forwarding table "outside"
First-hop interface is Port-channel20
Track 5
IP route 192.76.34.192 255.255.255.252 reachability
Reachability is Up (connected)
4 changes, last change 12w0d
Delay up 2 secs, down 2 secs
VPN Routing/Forwarding table "outside"
First-hop interface is Port-channel47
So you can see that aside from the interface numbering used in the development environment, the configuration used is the same.
I’ll simulate a failure of the inside link between the router and our active Linux firewall host by shutting down the associated interface (Port-channel10). I’ve also enabled debugging of tracking objects using the ‘debug track’ command which simplifies the demonstration and saves me the effort of manually interrogating the routing table or the tracking object to verify that the change took place:
Rack1SW3#conf t
Rack1SW3(config)#int po10
Rack1SW3(config-if)#shut
Rack1SW3(config-if)#
^Z
Rack1SW3#
*May 24 04:35:39.488: %LINEPROTO-5-UPDOWN: Line protocol on
Interface Port-channel10, changed state to down
Rack1SW3#
*May 24 04:35:40.452: %LINK-5-CHANGED: Interface FastEthernet1/0/9,
changed state to administratively down
*May 24 04:35:40.469: %LINK-5-CHANGED: Interface FastEthernet1/0/10,
changed state to administratively down
*May 24 04:35:40.478: %LINK-5-CHANGED: Interface Port-channel10,
changed state to administratively down
*May 24 04:35:41.459: %LINEPROTO-5-UPDOWN: Line protocol on
Interface FastEthernet1/0/9, changed state to down
Rack1SW3#
*May 24 04:35:41.476: %LINEPROTO-5-UPDOWN: Line protocol on
Interface FastEthernet1/0/10, changed state to down
Rack1SW3#
*May 24 04:35:52.364: Track: 2 Down change delayed for 2 secs
Rack1SW3#
*May 24 04:35:54.369: Track: 2 Down change delay expired
*May 24 04:35:54.369: Track: 2 Change #109 IP route 192.76.34.92/30,
connected->no route, reachability Up->Down
*May 24 04:35:54.797: Track: 1 Down change delayed for 2 secs
Rack1SW3#
*May 24 04:35:56.802: Track: 1 Down change delay expired
*May 24 04:35:56.802: Track: 1 Change #115 list, boolean and
Up->Down(->30)
OK, so we can see above that the Port-channel went down. I’m representing the backup path in my development scenario using loopback interfaces and floating routes have been configured using these pretend links. These routes should now have been installed in the routing table so to verify this, I checked which next-hop interface was being selected for some example destinations within each of the VRFs using the ‘show ip cef’ command:
Rack1SW3#sh ip cef vrf inside 10.16.136.1
10.16.0.0/12
nexthop 192.76.34.57 Loopback20
Rack1SW3#sh ip cef vrf inside 8.8.8.8
0.0.0.0/0
nexthop 192.76.34.97 Loopback10
Rack1SW3#sh ip cef vrf outside 192.76.8.1
192.76.8.0/26
nexthop 163.1.120.5 Loopback40
Rack1SW3#sh ip cef vrf outside 8.8.8.8
0.0.0.0/0
nexthop 192.76.34.209 Loopback30
So this looks to work for our pretend failure scenario, but will it recover? To find out, I brought interface Port-channel10 back up:
Rack1SW3(config)#int po10
Rack1SW3(config-if)#no shut
Rack1SW3(config-if)#
^Z
Rack1SW3#
*May 24 04:37:39.411: %LINK-3-UPDOWN: Interface Port-channel10,
changed state to down
*May 24 04:37:39.411: %LINK-3-UPDOWN: Interface FastEthernet1/0/9,
changed state to up
*May 24 04:37:39.411: %LINK-3-UPDOWN: Interface FastEthernet1/0/10,
changed state to up
Rack1SW3#
*May 24 04:37:43.832: %LINEPROTO-5-UPDOWN: Line protocol on
Interface FastEthernet1/0/9, changed state to up
*May 24 04:37:44.075: %LINEPROTO-5-UPDOWN: Line protocol on
Interface FastEthernet1/0/10, changed state to up
Rack1SW3#
*May 24 04:37:44.830: %LINK-3-UPDOWN: Interface Port-channel10,
changed state to up
*May 24 04:37:45.837: %LINEPROTO-5-UPDOWN: Line protocol on
Interface Port-channel10, changed state to up
Rack1SW3#
*May 24 04:37:52.422: Track: 2 Up change delayed for 2 secs
Rack1SW3#
*May 24 04:37:54.427: Track: 2 Up change delay expired
*May 24 04:37:54.427: Track: 2 Change #110 IP route 192.76.34.92/30,
no route->connected, reachability Down->Up
*May 24 04:37:54.720: Track: 1 Up change delayed for 2 secs
Rack1SW3#
*May 24 04:37:56.725: Track: 1 Up change delay expired
*May 24 04:37:56.725: Track: 1 Change #116 list, boolean and
Down->Up(->40)
I then repeated my previous show ip cef tests:
Rack1SW3#sh ip cef vrf inside 10.16.136.1
10.16.0.0/12
nexthop 192.76.34.29 Port-channel48
Rack1SW3#sh ip cef vrf inside 8.8.8.8
0.0.0.0/0
nexthop 192.76.34.93 Port-channel10
Rack1SW3#sh ip cef vrf outside 192.76.8.1
192.76.8.0/26
nexthop 163.1.120.1 Port-channel20
Rack1SW3#sh ip cef vrf outside 8.8.8.8
0.0.0.0/0
nexthop 192.76.34.193 Port-channel47
Great! So failure and recovery scenarios have tested successfully.
Final thoughts
I am generally very pleased with the routing and failover solution that’s been built for the new infrastructure. I think of particular benefit is its relative simplicity, especially when compared with the mechanisms used in the previous infrastructure.
It’s also much easier to initiate a failover with this new mechanism say if for some reason you specifically wanted the standby path to be used instead of the active one. This can be useful for carrying out any configuration changes or maintenance work on one of the Linux hosts for instance. This can either be executed by shutting down an interface on the host, or one on the switch within the active path. Then in around 5 seconds, hey presto! Traffic starts to flow over the other path!
Configuring an active/active scenario in the longer-term may be a better way forward ultimately. I’ve had some thoughts on using Policy-Based Routing (PBR) on the networking side to manipulate the next-hop of routing decisions based on the internal client source IP address. When used in conjunction with two distinct external NAT pool IP ranges (one per firewall host) this could be just the ticket to achieve a workable active/active scenario. Time-permitting, I’ll be looking to test this within our development environment before contemplating this for production service. Assuming it worked OK in testing, I think it would also be worth weighing up the time and effort that this configuration would involve against the relative benefits and risks to the service.
That concludes my coverage on the routing/failover setup for the networking-side of the new eduroam back-end infrastructure. Thanks for reading!