 In previous posts, I discussed the roles of routing and NATing in the new eduroam infrastructure . In one sense, that is all you need to create a Linux NAT firewall. However, the setup is not very resilient. The resulting service would be littered with single points of failure (SPoF), including:
In previous posts, I discussed the roles of routing and NATing in the new eduroam infrastructure . In one sense, that is all you need to create a Linux NAT firewall. However, the setup is not very resilient. The resulting service would be littered with single points of failure (SPoF), including:
- The server – Reboots would take the service down, for example when installing a new kernel.
- Ethernet cables – With one cable leading to “inside” the eduroam network and and one cable leading to “the outside world”, it would only take either cable to develop a fault to result in a complete service outage.
Solving the first SPoF is easy (at least for me)! I can just install two Linux boxes, identical to each other, and leave John to figure out how to route the traffic to each. We currently have an active-standby set up where all traffic flows through one box until the event that the primary is unavailable. No state is shared between these boxes currently, which means that a backup server promoted to active duty will result in lost connection data and DHCP leases. Because of this we will only do kernel reboots during our designated Tuesday morning at-risk period unless there is good reason to do otherwise. State sharing of connection data and DHCP leases is possible but we would have to weigh up the advantages against the added complexity of configuration and the added headache of maintaining lock step between the two servers.
As you may have guessed from its title, this blog post is going to discuss bonding, which (amongst other things) solves the problem of having any single cable fail.
Automatic fail over of multiple links
When you supplement one ethernet cable with another on Linux, you have a number of configuration choices for automatic failover, so that when one cable goes down all traffic goes through the remaining cable. When taking into account that the other end is a Cisco switch, the choices are narrowed slightly. Here are the two front runners:
Equal-cost multi-path routing (ECMP, aka 802.1Qbp)
Multipath routing is where multiple paths exist between two networks. If one path goes down, the remaining ones are used instead.
Each route is assigned a cost. The route with the lowest overall cost is chosen. When a link goes down, a new path is calculated based on the costs of the remaining routes. This can take a noticeable amount of time. However, with multiple routes having the same cost, the failover can be near instantaneous. The multiple routes can be used to increase bandwidth, but our main goal is resiliency.
As a point of interest, our previous eduroam (and current OWL) infrastructure uses multipath (not equal-cost) to fail over between the active and standby NAT boxes. On either side of these two boxes sits a switch and across these two switches is defined two routes, one through the active NAT server, the other through the standby. The standby has a higher cost by virtue of an inflated hop count so all traffic flows through the active. A protocol called RIPv2 is used to calculate route costs and when a link goes down, the switches re-evaluate the costs of routing traffic and decide to send traffic through the standby. This process takes approximately 5 seconds.
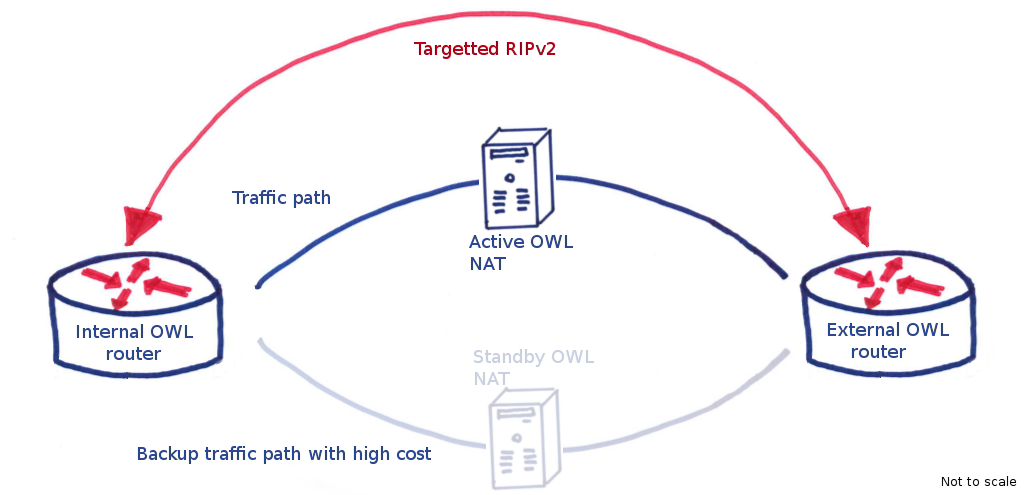
OWL routing has RIPv2 going through two NAT servers, each route having a different cost. When the primary link goes down, the routes are recalculated and all traffic subsequently flows through the standby path, which has an inflated hop count to create a higher routing cost.
The new eduroam switches use object tracking to manage fail over of the individual servers. This is independent of link aggregation explained below.
Link Aggregation Control Protocol (LACP, aka 802.3ad, aka 802.1ax, aka Cisco Etherchannel, aka NIC teaming)
This is the creation of an aggregation group so that the OS would present the two cables as one logical interface (e.g. bond0). This makes configuration of the NAT service much simpler as there is only one logical interface to worry about when configuring routes and firewall rules.
ECMP has its advantages (for one, the two links can be different speeds and can span across multiple Linux firewalls [see MLAG below]), but LACP is the aggregation method of choice for many people and we were happy to go with convention on this one.
The name’s bond, LACP bond
LACP links are aggregated into one logical link by sending LACPDU packets (or, more accurately, LACPDU frames if you have read the previous blog post) down all the physical links you wish to aggregate. If an LACPDU reply is subsequently received from the device at the other end, then the link is active and added to the aggregation group. At the same time, each interface is monitored to make sure that it is up. This happens much more frequently and is used to check the status of the cables between the two devices. After all, you are more likely to suffer a cut cable scenario than a misconfiguration once everything is set up and deployed.
How traffic is split amongst the different physical cables will be discussed later but for now it suffices to say that all active cables can be used to transmit traffic so if you have two 1Gb links, the available bandwidth is potentially 2Gb. While some people aggregate links for increased bandwidth, we are solely using it for improved resiliency. Any increased throughput is a bonus.
When receiving traffic through bonded interfaces, you do not necessarily know through which physical interface the sending device sent them; the decision rests solely on the sending device. However, there are some assumptions that are fairly safe, like all traffic for a single connection is sent via the same physical interface (subject to the link not going down mid connection, obviously.)
How can you use it? A simplified picture
Two devices communicating using a bonded connection of two cables will use both those cables to transmit data, failing over gracefully should any one cable fail. In fact you are not limited to two cables. The LACP specification says that up to eight cables can be used (link-id, which is unique for each physical interface can be an integer between 1 and 8.) In reality four may be a lower limit imposed by your hardware.
A schematic diagram of how the switches either side of the NAT server are connected using bonding is shown below.
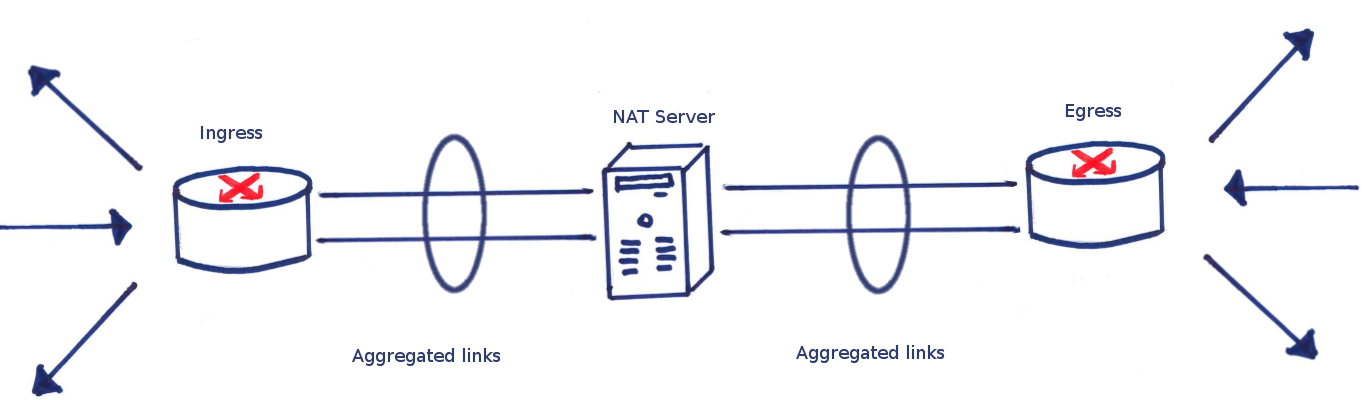
A simplistic view of how link aggregation is represented for eduroam using standard drawing conventions
Here we see two links either side of the NAT server, with circles around them. This is the convention for drawing a link aggregation.
How do we use it? The whole picture
In reality the diagram above is incomplete. The new eduroam service is designed to be a completely redundant system. Every connection has two links aggregated and every device is replicated so that no one cable nor device can bring down the service. In fact, with every link aggregated and there being a backup server, a minimum of four cables would need to fail for the service to go down, up to a possible six.
Below is a diagram of all the link aggregations in action.

The full picture of where we use link aggregation for eduroam.
This diagram is a work of art (putting to shame my felt-tip pen efforts) created by John and described in his earlier blog post. I would recommend reading that blog post if you wish to understand the topology of the new eduroam infrastructure. However, this blog series takes a look at the narrow purview of what the Linux servers should be doing, and so no real understanding of the eduroam topology is required to follow this.
Installing and setting up LACP bonding on Debian Linux
I should point out that nothing I am saying here cannot be gleaned from the Linux kernel’s official documentation on the subject. That document is well written and very thorough. If I say anything that contradicts that, then most likely it is me in error. In a similar vein, you can find a great number of blog posts on link aggregation that contradict the official documentation and each other.
As an example, you will encounter conflicting advice about the use of ifenslave to configure bonding. For example, some posts will say that it is the correct way of doing things, others will say that its use is deprecated and that you should use iproute2 and sysfs.
Which is correct? Well, for Debian (which we use) it’s a mixture of both. As I understand it, there was a program ifenslave.c that used to ship with Linux kernels which handled bonding. This is now deprecated. However, Debian has a package called ifenslave-2.6 which is a collection of shell scripts which are run to help create a bonded interface from the configuration files you supply. In theory you can dispense with these scripts and configure the interface yourself using sysfs, but I wouldn’t recommend it. These scripts are placed in the directories under /etc/network and are run for every interface up/down event.
So, with that in mind, let’s install ifenslave-2.6:
apt-get update && apt-get install ifenslave-2.6
Now we can define a bonded interface (let’s call it bond0) in the /etc/network/interfaces file. This file does not need to have the eth5, eth7 devices defined anywhere else in the interfaces file (we do define them, for reasons to be explained in, you guessed it, a later blog post.)
auto bond0
iface bond0 inet static
bond-slaves eth7 eth5
address 192.168.34.97
netmask 255.255.255.252
bond-mode 802.3ad
bond-miimon 100
bond-downdelay 200
bond-updelay 200
bond-lacp-rate 1
bond-xmit-hash-policy layer2+3
txqueuelen 10000
up /etc/network/eduroam-interface-scripts/bond0/if-up
down /etc/network/eduroam-interface-scripts/bond0/if-down
Let’s get rid of the cruft so that just the relevant stanzas remain (the up/down scripts are for defining routes and starting and stopping the DHCP server.)
iface bond0 inet static
bond-slaves eth7 eth5
bond-mode 802.3ad
bond-miimon 100
bond-downdelay 200
bond-updelay 200
bond-lacp-rate 1
bond-xmit-hash-policy layer2+3
All these lines are very well described in the official documentation so I will not explain anything here in any depth, but to save you the effort of clicking that link, here is a brief summary:
- LACP bonding (
bond-mode). - Physical links eth5 and eth7 (
bond-slaves). - Monitoring on each physical link every 100 milliseconds (
bond-miimon), with a disable, enable delay of 200 milliseconds (bond-downdelay,bond-updelay) should the link change state. - Aggregation link checking every second (
bond-lacp-rate). The default is 30 seconds which probably would suffice, but it means misconfigurations are detected faster.
The one option I have left out is the bond-xmit-hash-policy which probably needs a fuller explanation.
bond-xmit-hash-policy
I said earlier that I would explain how traffic is split across the physical links. This configuration option is it. In essence the Linux kernel is using a packet’s properties to assign a number to it (link-id), which is then mapped to a physical cable in the bond. Ideally you would want each connection to go through one cable and not be split.
The default configuration option is “layer2” which uses the source and destination MAC address to determine the link. Bonded interfaces share a MAC address across their physical interfaces on Linux, so when the two ends are configured as a linknet comprising just two hosts, there are only two MAC addresses in use, those of the source and destination. In other words, all traffic will be sent down one physical link!
Now, this would be fine. Our bonding is used for resilience, not for increased bandwidth and since the NICs are 10Gb capable Intel X520s, there should be enough bandwidth to spare (we currently peak at around 1.7Gb/s in term time.)
However, we would prefer to use both links evenly if possible for reasons of load balancing the 4500-X switches at the other end of the cables. We use microflow policing on the Cisco boxes and as I understand it, these work better with an even distribution of traffic. For that reason, we specify a hash-policy of layer2+3 which includes the source and destination IP addresses to calculate the link-id. The official documentation has an explanation of how this link-id is calculated for each packet.
Monitoring LACP bonding on Debian Linux
True to Unix’s philosophy of “everything is a file”, you can query the state of your bonded interface by looking at the contents of the relevant file in /proc/net/bonding:
$ cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: IEEE 802.3ad Dynamic link aggregation Transmit Hash Policy: layer2+3 (2) MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 200 Down Delay (ms): 200 802.3ad info LACP rate: fast Min links: 0 Aggregator selection policy (ad_select): stable Active Aggregator Info: Aggregator ID: 1 Number of ports: 2 Actor Key: 33 Partner Key: 11 Partner Mac Address: 02:00:00:00:00:63 Slave Interface: eth7 MII Status: up Speed: 10000 Mbps Duplex: full Link Failure Count: 2 Permanent HW addr: a0:36:9f:37:44:da Aggregator ID: 1 Slave queue ID: 0 Slave Interface: eth5 MII Status: up Speed: 10000 Mbps Duplex: full Link Failure Count: 2 Permanent HW addr: a0:36:9f:37:44:ca Aggregator ID: 1 Slave queue ID: 0
Here we can see basically the same configuration we put into /etc/network/interfaces along with some useful runtime information. A particularly useful line is the Link Failure Count, which shows that both physical links have failed twice since the last reboot. As long as these failures did not occur simultaneously across the two physical links, the service should have remained on the primary server (which it did.)
Notice how there isn’t an IP address in sight. This is because LACP is a layer 2 aggregation so it does not need to know about any IP address to function. The IP addresses we configured in /etc/network/interfaces are those built on top of LACP and are not part of LACP’s function.
What they don’t tell you in the instructions
So far so good. If you’re using this blog post as a step by step guide, you should successfully have bonding so that any link in an aggregation can go down and you wouldn’t even notice (unless your monitoring system is configured to notify you of physical link failure.)
However, there are some things that tripped me up. Hopefully by explaining them here I will save a little headache for anyone who wishes to tread a similar path to mine.
Problem 1: Packet forwarding over bonded links
By default, Linux has packet forwarding turned off. This is a sensible default, one we’d like to keep for all interfaces (including management interface eth0), except for the interfaces we require to forward: bond0 and bond1. You can configure this, as we’ve done using sysctl.conf
net.ipv4.conf.default.forwarding=0 net.ipv4.conf.eth0.forwarding=0 net.ipv4.conf.bond0.forwarding=1 net.ipv4.conf.bond1.forwarding=1
Now looking at this, you’d think this would work, and that eth0 wouldn’t forward packets but bond0 and bond1 will.
Wrong! What actually happens is that neither bond0 nor bond1 will forward packets after a reboot. What’s going on? It’s a classic dependency problem, and one that has been in Debian for many years. The program procps, which sets up the kernel parameters at boot, runs before the bonding drivers have come up. The Debian wiki has solutions, of which the one we picked is to run “service procps reload” again in /etc/rc.local. Yes, you do still get error messages at boot and there is a certain whiff of a hack about this, but it works and I’m not going to argue with a solution that works and is efficient to implement, no matter how inelegant.
Problem 2: Traffic shaping on bonded links
This really isn’t a problem I was able to solve. In the testing phases of the new eduroam, we looked at traffic shaping using the Linux boxes and the tc command. We could get this to reliably shape traffic for physical interfaces, but applying the same queueing methods on bond0 proved far too unreliable. There are reports [1][2] that echo my experiences, but even running the latest kernel (3.14 at the time of deployment) did not fix this, nor did any solutions that I found on the web. In the end we abandoned the idea of traffic shaping on the Linux boxes and instead used microflow policing on the Cisco 4500-X switches, which as it happens works very well.
I hope to write at least a summary of traffic shaping on Linux as it’s considered a bit of a dark art and although I didn’t actually get anywhere with it, hopefully I can impart a few things I learnt.
Problem 3: Mysterious dropped packets
You may remember me mentioning in the last blog post that we backported the Jessie kernel into these hosts. The reason wasn’t a critical failure of the Wheezy default kernel, but it irked me enough to want to remedy it.
Before kernel release 3.4, there was a bug where LACPDU packets were received and processed, but then discarded as an unknown packet by the kernel, in the process incrementing the RX dropped packets counter. This counter is an indicator that something is wrong, so seeing this number increment at a rate of several a second is quite alarming. The bug was fixed in 3.4 (main patch can be found at commit 13a8e0.) Unfortunately Debian Wheezy uses kernel 3.2 by default. The solution was to install a backported kernel. We have not experienced any increase in server reboots because of this, although the possibility of course is there as Jessie is a constantly moving target.
Running 3.14 for the past 35 days, we have forwarded around 200000000000 packets, and dropped 0! For those interested, 2× 1011 packets is, in this instance, 120TB of data.
What I looked into but didn’t implement
As is becoming traditional with this blog series, here are a few things that I looked into, but for some reason didn’t implement (mostly time constraints). Usual caveats apply.
Clustered firewall
At the moment we have a redundant setup. If the primary NAT server falls over, or goes offline, the secondary will receive traffic. The failover is 2 seconds and we hope that is fast enough for an event that doesn’t occur too often (the old servers have an uptime of 400 days and counting.)
When the failover happens, the secondary starts with a completely blank connection tracking table, which is filled as new connections are established. This means that already existing connections are terminated by the NAT firewall and have to be re-established.
However, it is possible to share connection tracking data between these two servers. This means that should the primary go down, the secondary should be able to NAT already established connections, and all people will notice is a two second gap when data is streamed.
This functionality is provided by conntrackd, which is part of the netfilter suite of tools. If we were to use it, we would even be able to provide active-active NAT thereby spreading the bandwidth across both servers. It’s something we can consider in the future, but at the moment, it’s overkill for our needs.
Multi-Chassis link aggregation (MLAG)
When I said above that the LACP we have implemented was to protect us from a faulty cable, I was in fact omitting a rather big fact. The cables from the Linux server actually go to two separate Cisco 4500-X switches so in other words, not only is it guarding against a failed cable, but also a failed switch. Eagled eyed readers may already have spotted this in John’s diagram above.
Now normally this isn’t possible because LACP requires all physical interfaces to be on the same box, but this is a special case. The two boxes are set up as a VSS pair which means that the two physical boxes are presented as one logical switch. When one physical switch fails, the logical switch will lose half its ports, but otherwise will carry on as if nothing has happened.
Now, with this conntrackd daemon I mentioned above, is it possible to achieve a similar effect with two Linux servers, where a bond0’s slave interfaces are shared across multiple physical servers? Well, in a word, no. MLAG is a relatively new technology and as such has been implemented differently by different vendors using proprietary techniques. We use Cisco’s VSS, but even Cisco themselves they have multiple technologies to achieve the same effect (vPC). Until there is a standard on which Linux can base its implementation, it’s unlikely one will exist.
In Linux’s defence, there are ways around this. You could set up your cluster with ECMP via the switches either side of them, and any link that fails gets its traffic rerouted through the remaining links. The conntrackd would mean that the connection would stay up. However this is speculation as I haven’t tried this.
Coming up next
That concludes this post on bonding. Coming up next is a post on buying hardware and tuning parameters to allow for peak performance.
It just amazing article and got to know much info. Have a question
Is it possible to put slave members in bond and make bond not to select the slave for traffic ? So just looking for slave to be in a mode where it will not rx/tx any traffic ?
Could you point if there is any such mode ?
Do you mean you want a bond where all traffic goes through one slave interface, but the traffic goes through a secondary should the primary fail? Does the “active-backup” mode suit your needs?
Thanks for this. I have bonding working now, but it will only use 3 of my 4 NICs for some reason. When I look at /proc/net/bonding/bond0 I can see that it is assigning my 4th NIC (eth3) a different “Aggregator ID.” I cannot find any way to force this ID. Know of one or know of any reason it might not want to add my 4th NIC?
Without looking at your configuration it is hard to say. What is configured up the other end? The configuration is mutually decided by the two connected switches so even if all the configuration looks fine on one end, it may well be the other end that is causing the issue.
It seems the NAT post now requires Oxford login to view?
Link was broken in the post. Now fixed. Thanks for pointing that out!
The state changes can be easily shared between the two boxes allowing for active/backup if you use keepalived and contrackd. Thus you can reboot one of them with no downtime or at most 2 second but connections will persist and not be cut off!
Thanks Bjorn. I mentioned conntrackd in the post for persisting connections across multiple Linux boxes, but didn’t implement it due to time constraints (and other more important, but not interesting reasons). Keepalived is indeed a useful tool to manage failover, but in this case, the failover in this instance occurs on the (virtual) switches that sit either side of these NAT boxes using object-state tracking. The failover time is exactly as you suggest, two seconds.