This is a continuation of the series of posts examining the inner workings of eduroam and in particular Linux’s involvement in it. I had originally intended for this to be a post on both logging and monitoring. I now realize that they are worthy of their own posts. This one will cover the former and its scope has been expanded to include some background on perl and the regular expressions that we use to create and search through these logs.
It is a sad fact that we here in the Networks team are required to sometimes trace the activity of users using the eduroam service. I should say now that this an exception and we do not associate connections with users routinely (the process is fiddly and time consuming). However, regularly we receive notifications of people using the service to illegally download material and it is our job to match the information provided by the external party (usually the source port and IP address) to the user instantiating the connection. When the connection flows through a NAT, there is no end-to-end relationship between the two endpoints and so the connection metadata given by the external party is not enough on its own to identify the user. It is then up to us to match the connection info provided with the internal RFC1918 address that the end user was given, which in turn leads us to an authentication request.
This post can be thought of as two almost completely unrelated posts. The first section is about how the Linux kernel spits out NAT events for you to log. The second section is what was running through my head when I was writing the scripts to parse and search through this output. They can almost be read separately, but they make a good couple.
Conntrack – connection monitoring
It’s the kernel’s job to maintain the translation table required for NAT. Extracting that information for processing and logging is surprisingly not possible by default (possibly for performance considerations). To enable connection tracking in Debian, you will need to install the conntrack package:
# apt-get install conntrack
Now you can have the server dump all its connections that are currently active
# conntrack -L
tcp 6 src=10.30.253.59 dst=163.1.2.1 sport=.....
tcp 6 src=10.32.252.12 dst=129.67.2.10 sport=.....
...
You can also stream all conntrack event updates (e.g. new connections events, destroyed connections events)
# conntrack -E
You may see other blogs making mention of a file /proc/net/nf_conntrack, or even /proc/net/ip_conntrack. Reading these files provides similar functionality to the previous command, but it’s nowhere near flexible for us as you will see as the conntrack command can filter events and change the output format.
Filtering and formatting conntrack output
I’m going to start with the command we use, and then break it down piece by piece. This is what is fed into a perl script for further processing:
# conntrack -E -eNEW,DESTROY --src-nat -otimestamp,extended \
--buffer-size=104857600
Those flag’s definitions are in conntrack’s man pages, but for completeness, they are
-E ⇐ stream updates of the conntrack table, rather than dump the current conntrack table-eNEW,DESTROY ⇐ only print NEW and DESTROY events. There exist other events associated with a connection which we do not care about.--src-nat ⇐ only print NATed connections. Other connections, like SSH connections to the server’s management interface are ignored.-otimestamp,extended ⇐ Change the output format. The “timestamp” means that every event has a timestamp accompanying it. The “extended” includes the network layer protocol. This should always be ipv4 in our case but I have included it.--buffer-size=104857600 ⇐ When a program is outputting to another program or file, there may be a backlog of data as the receiving script or disk cannot process it fast enough. These unprocessed lines (or bytes I should say, since that’s the measure) are stored in a buffer, waiting for the script to catch up. By default, this is 200kB, and if that buffer overflows, then conntrack will die with an ENOBUF error. 200kB is a very conservative number and we did have conntrack die a few times due to packet bursts before we bumped the buffer-size to what it is now (100MB). Be warned that this buffer is in memory so be sure you have enough RAM before boosting this parameter.
Accurate timestamps
When you are tasked with tracing a connection back to a user, getting your times correct is absolutely crucial. It is for that reason that we ask conntrack to supply the timestamps for the events it is displaying. For a small-scale NAT, the timestamp given by conntrack will be identical to the time on the computer’s clock.
However, when there is a queue in the buffer, the time could be out, even by several seconds (certainly on our old eduroam servers, with 7200rpm disks this was a real issue.) While it’s unlikely that skewed logs will result in the wrong person being implicated, less ambiguity is always better and better timekeeping makes searching through logs faster.
Add bytes and packets to a flow
By default the size of a flow is not logged. This can be changed. Bear in mind that this will affect performance.
# sysctl -w net.netfilter.nf_conntrack_acct=1
This is one of those lines that is ignored if you place it in /etc/sysctl.conf, because that file is read too early in Debian’s booting routine. Please see my previous blog post for a workaround.
Post-processing the output using perl
Now I could almost have finished it there. Somewhere, I could have something run the following line on boot:
# conntrack -E -eNEW,DESTROY --src-nat -otimestamp,extended
--buffer-size=104857600 > /var/log/conntrack-data.log
I would then have all the connection tracking data to sift through later when required. There are a few issues with this:
- Log rotation. Unless this is taken into account, the file will grow until the disk becomes full.
- Verbosity and ease of searching. The timestamps are UNIX timestamps, and the key=value pairs change their meanings depending on where they appear in the line. Also, while the lines’ lengths are fairly short, given the number of events we log (~80,000,000 per day currently) a saving of 80 bytes per line (which is what we have achieved) equates to a space saving of 6.5GB per day. We compress our logs after three days, but searching is faster on smaller files, compressed or not.
If you’re an XMLphile, there is the option for conntrack to output in XML format. I have added line breaks and indentation for readability:
# conntrack -E -eNEW,DESTROY --src-nat -oxml,timestamp | head -3
<?xml version="1.0" encoding="utf-8"?>
<conntrack>
<flow type="new">
<meta direction="original">
<layer3 protonum="2" protoname="ipv4">
<src>10.26.247.179</src>
<dst>163.1.2.1</dst>
</layer3>
<layer4 protonum="17" protoname="udp">
<sport>54897</sport>
<dport>53</dport>
</layer4>
</meta>
<meta direction="reply">
<layer3 protonum="2" protoname="ipv4">
<src>163.1.2.1</src>
<dst>192.76.8.36</dst>
</layer3>
<layer4 protonum="17" protoname="udp">
<sport>53</sport>
<dport>54897</dport>
</layer4>
</meta>
<meta direction="independent">
<timeout>30</timeout>
<id>4271291112</id>
<unreplied/>
</meta>
<when>
<hour>16</hour>
<min>07</min>
<sec>18</sec>
<wday>5</wday>
<day>4</day>
<month>9</month>
<year>2014</year>
</when>
</flow>
As an aside, you may notice an <id> tag for each flow. That would be a great way to link up events into the same flow without having to match on the 5 tuple. However I cannot for the life of me figure out how to extract that from conntrack in any format other than XML. (Update: See Aleksandr Stankevic’s comment below for information on how to do this.)
If your server is dealing with only a few events per second, this is perfect. It outputs the data in an easily searchable format (via a SAX parser or similar). However, for us, there are some major obstacles, both technical and philosophical.
- It’s verbose. Bear in mind the example above is just one flow event! At roughly five times as verbose as our final output, our logs would stand at around 50GB per day. When term starts we would seriously risk filling our 200GB SSDs.
- It’s slow to search. As you shall eventually see, the regexp for matching conntrack data below is incredibly simple. To achieve something similar with XML would require a parser, which, while written by people far better at coding than I, will never be as fast as a simple regexp.
- If the conntrack daemon were to die (e.g. because of an ENOBUF error), then restarting it will create a new XML declaration and root tag, thus invalidating the entire document. Parsers may (and probably should) fail to parse this as it has now become invalid XML.
This is the backdrop to which a new script was born.
conntrack-parse
The script that is currently in use is available online from our servers.
The perl script itself is fairly comprehensively documented (you do all document your scripts, right?) It has a few dependencies, probably the only exotic one being Scriptalicious, but even then that is not strictly required for it to run, it just made my life easier for passing arguments to the script. There is nothing special about the script itself; it can be run on any host running as a NAT server so long as there is a perl interpreter and the necessary dependencies. If you have turned off flow size accounting then the script will still work. All that will happen is that the relevant fields will be left blank.
I am presenting it, warts and all, for your general information and amusement. It includes a fairly bizarre workaround (or horrible hack, depending on your perspective) to get our syslog server to recognize the timestamp. This is clearly marked in the code and you are free to alter those lines to suit your needs.
Things to note
- This script is set to run until the end of time. Should it exit, it has no mechanism to restart itself. This should be the job of your service supervision software. We use daemontools but systemd would also work.
- If you issue a SIGHUP to a running instance of this script, then the output file is re-opened. This is useful for logrotate, which we use to rotate the logs every day.
The script changes the flow’s data into a CSV format. It’s no coincidence that the NATed source IP and source port are adjacent, as to match the line on these two criteria would involve the regular expression
$line =~ /;$SOURCE_IP;$SOURCE_PORT;/;
The actual matching is a little more involved than this as we have to match on the timestamp as well (see below), but the searching for the flow is relatively quick, and takes a few minutes to search through an entire day’s worth of logs.
Making the conntrack-parse script run as fast as possible
Firstly, if speed is important, then perl may not be the first language to reach for. Writing the equivalent procedures in C or for the JVM will see significant CPU cycle savings when parsing the output. However, since we work almost exclusively in perl here in the Networks team, it makes sense to go with what we know. Currently the script is using a CPU core which is 20% busy. The flip-side of that is that there is 80% of the core that is not being used, so I’m not overly concerned that there is anything that needs to be done to the script as yet. I am also fairly confident that any bottlenecks in the eduroam service will cap connections long before conntrack-parse cannot process the lines fast enough.
With that out the way, there are techniques and tips that you should consider while writing perl, or at least they were in my thoughts when I was writing the script.
Don’t create objects when a hash will do
The object orientated paradigm seems a bit passé these days as more and more languages jump on the functional bandwagon. I would say that in this case, a common sense approach of removing abstraction layers that are there due to some kind of programming paradigm purity can only lead to speed gains (again, and this is the last time I will point this out, perl in itself is several layers of abstraction above the CPU instructions being performed so using another language could also help here.)
A temptation would be to model a line as a “line object”. Therefore, you would have
print $line->inside_source_ip;
or even worse
print $line->inside->source_ip;
perl in some sense arrived late to the object orientated party and in this case it’s a blessing as it’s very easy to see how to use a simpler hash that is faster for attribute lookups and garbage collection. If this were written in Java, the temptation to model everything as objects would be higher, although of course the JVM has been optimized heavily for dealing with object orientated code.
Finally, whatever you do, don’t use Moose. It has its place. That place isn’t here as performance will suffer.
Print early, print often
This is a rule that I’ve broken, and I have to beg forgiveness for it. In the script you will see something akin to
print join(‘;’, @array);
That is creating a new string by concatenating all elements in a list, and then printing the output. An alternative approach would be
print $array[0], ‘;’, $array[1], ‘;’, …..
Programming Perl, the defacto standard in perl books says that this may help, or it may not. I would say that here, printing without joining would be faster.
Keep loops lean
Everything that happens in a for loop is evaluated for every iteration of that loop. Say I had accidentally forgotten to move a line from inside the loop to outside, a mapping hash for example
while ( $line = <> ) {
my $state_mapper = {
'[NEW]' => 'start',
'[DESTROY]' => 'stop',
}
...
}
This variable will be created for every line. It’s an invariant variable and perl is not (yet) smart enough to factor this out of the loop. You should write the following
my $state_mapper = {
'[NEW]' => 'start',
'[DESTROY]' => 'stop',
};
while ( $line = <> ) {
....
}
It almost feels patronizing writing this, but I have certainly been guilty of forgetting to move invariant variables out of a loop before.
I should point out that the following code is OK
use constant {
DEBUG => 0,
};
while ( $line = <> ) {
print "DEBUGGING: $line" unless DEBUG;
....
}
This is a special case where perl recognizes that the print statement will never be called and will thus optimize out the line entirely from the compiled code.
Optimizing the search: faster regular expressions

Obligatory comment about the obligatoriness of an XKCD reference
Now that the logs have been created, we need to search them. At 10GB of data per day, just writing any old regular expression and running it would be tolerable, but it helps to think a little bit about optimizing the regular expression first. Vast swathes of ink have been spilt trying to impart the best way of crafting regular expressions (shortly behind SQL query optimization). I’m no expert on the matter, but here are some experiences I can give. I would say that the primary aim is to accurately match the line you are looking for. If you only have to search infrequently and it takes a minute or two to complete, then grab yourself a cup of tea while it finishes; the important thing is that the regular expression returns the match that you wanted.
Make the matches accurate
Let’s start with an easy one and it’s less to do with performance (although it does affect it) and more to do with actually finding what you want. An inaccurate match is a disaster to us as it will potentially point the finger at the wrong person when we are tracing connections and we will have to run the search again.
Say you are looking for an IP address 10.2.2.2, a novice might try
$line =~ /10.2.2.2/;
That’s wrong on many levels. It will match, but not for the reasons you’d naively think. The point to remember is that a dot matches any character, including the full-stop! This will correctly match our IP address, but will also include false positives, such 10.252.2.4, 10.2.242.1, 1012;202 and so on. The novice tries again…
$line =~ /10\.2\.2\.2/;
That’s better, but still wrong. This will match 10.2.2.21. Since we know our data is semicolon delimited, let’s add them into the regular expression…
$line =~ /;10\.2\.2\.2;/;
This is now a literal string match as opposed to a normal regular expression. This leads me onto the next topic.
Use literal string matching
Use a simple literal string wherever possible. perl is smarter than your average camel and will optimize these regular expressions by using a Boyer-Moore search [BM search] algorithm. This algorithm has the unusual property that the longer the pattern that you wish to match, the faster it performs! The wikipedia article has a description of how this algorithm is implemented. The following is a simplification that just shows how it can be faster. Please skip this if you have no interest in searching or in algorithms, just bear in mind that a short literal regular expression might actually be slower than a longer one.
Let’s take an example where there’s a match to be made. I apologize for the awful formatting of this if you are viewing this page using the default style. Also, anyone reading this page using a screen reader is encouraged to read the wikipedia article instead as what follows is a very visual representation of the algorithm that does not translate onto a reader.
Here is the text that you wish to match, $line and the regular expression pattern you wish to match it with, $regexp
$line = 'start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;';
$regexp = qr/;192\.76\.8\.23;9001;/;
Let’s line the text and the pattern up so that they start together
↓
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
↑ ✗
The key is to start the matching at the end of the pattern. Clearly “;” != “5”, so the match has failed at the first character. The match failed, and it has been indicated with a cross “✗” but the character in the text (“5”) might be in the pattern. We check if there is a 5 in the pattern. There isn’t, so we know that we can shift the pattern by the entire pattern’s length, since that character in the text cannot appear anywhere in our match. Thus, the pattern is shifted to align the two arrows.
↓
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
↑✗
Here’s where it gets interesting (or at least slightly more interesting). The match has failed, but the character in the text (“1”) is present in the pattern (represented by the upward arrow). In fact, there are two but for this to work we have to take the one nearest to the end. In this instance, it’s the next one along. We need to shift the pattern by one, again to align the arrows..
↓
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
↑ ✗✓✓
We’ve successfully matched two characters. Unfortunately the third doesn’t match (“0” != “2”). However, there is a 2 in the pattern so we will shift it to align the 2s
↓
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
↑ ✗
The following comparisons and necessary shifts will be made with no further comment
↓
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
↑ ✗
↓
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
↑ ✗
↓
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
↑ ✗
Text => start tcp;10.23.253.45;208.146.36.21;55928;9001;;;208.146.36.21;192.76.8.23;9001;55928;;
Pattern => ;192.76.8.23;9001;
✓✓✓✓✓✓✓✓✓✓✓✓✓✓✓✓✓✓
And there you have a match, with 27 character comparisons as opposed to over 90 using the naive brute-force searching algorithm. Again, I stress this is a simplification. The string matching example gave me no opportunity to show another facet of the BM search called “The good suffix rule” (which is just as well, since it’s quite complicated to explain), but I hope that this in some way demonstrates the speed of a literal string searching operation.
Don’t do anything fancy just because you can
In real life, we have to match the time as well as the ip and port. The temptation is to write this in one regular expression
$line =~ /^2014-09-05T10:06:49+01:00 127\.0\.0\.1 start tcp;.*;192\.76\.8\.23;9001;/;
This in itself is probably fine because perl will optimize this into a BM search on the date, and then if there’s a match, continue with the full regexp involving the IP and port. The trouble begins when you need to do a fuzzy match. On our old eduroam servers, the date and time logged could be several seconds out (10 seconds sometimes). That’s fine, let’s make for a fuzzy match of the time
$line =~ /^2014-09-05T10:06:(39|[4-5][0-9])+01:00 127\.0\.0\.1 start tcp;.*;192\.76\.8\.23;9001;/;
But wait! What about if the offending line were on the hour? Say we wanted to match at 10:00:00+01:00 with a wiggle room of 10 seconds, that would be:
$line =~ /^2014-09-05T(?:09:59:5[0-9]|10:00:(?:0[0-9]|10))+01:00 127\.0\.0\.1 start tcp;.*;192\.76\.8\.23;9001;/;
What about 10:00:09? No sweat:
$line =~ /^2014-09-05T(?:09:59:59|10:00:(?:0[0-9]|1[0-9]))+01:00 127\.0\.0\.1 start tcp;.*;192\.76\.8\.23;9001;/;
Woe betide anyone who has to match on a connection that occurred at midnight as that will span two files! These regular expressions don’t look so pretty, to me and probably to the server actually running them against our log files.
These regular expressions change form depending on the time you wish to match which would tax even the most fervent regular expression fanatic, and they’re not an optimized way of searching as they use something called backtracking, which when used too much can slow text searching down to a crawl (in pathological cases, on current hardware it can take millennia for an 80 character pattern to match an 80 character string).
In this case, there are some efficiency gains to be done by performing some logic outside of the matching. For example, what about matching on just the ;IP;port;, and verifying the time on the matches?
if ( $line =~ /;$IP_ADDRESS;$SOURCE_PORT;/ ) {
if ( within_tolerances($line, $TIMESTAMP) ) { return $line }
}
Here we are doing a fast literal search on the IP and port, and doing the slow verification of timestamp only on the matching lines. So long as the match doesn’t occur on too many lines, the speed increase compared with the one regular expression can be substantial.
In fact, this is approaching something close to the script we use to trace users, although that script is more involved as it takes into account there may be a line closer to $TIMESTAMP that occurs after the first match, and it exits early after the log line timestamps are greater than $TIMESTAMP + $TOLERANCE.
Is it any faster though? The difficulty is that the perl regular expression compiler uses many tricks to optimize searching (varying even from one version to the next), so things that are equivalent in terms of matching but look to you as different in terms of efficiency may not be to perl as it may have optimized them to equivalent expressions. The proof of the pudding is in the eating and I would encourage you to experiment.
However, there is the important consideration of writing legible regular expressions and code. You may understand a regular expression you have written, but will you recognize it tomorrow? Will a colleague? Here is a regular expression in one of our RADIUS configuration files that I found, written without comment. I have a fairly good idea of what it does now, but it took a while to penetrate it. Answers on a postcard please!
"%{User-Name}" !~ /\\\\?([^@\\\\]+)@?([-[:alnum:]._]*)?$/
Exit from the loop once you’ve found a match.
This seems obvious, but bears saying nonetheless. If you know that a match occurs only once in a file (or you only need the first match) then it makes no sense to carry on searching through the log file. In perl this is easily achieved and most people will do this without thinking:
sub find {
.....
while ( $line = <FH> ) {
if ( $line =~ /$pattern/ ) {
close FH;
return $line;
}
close FH;
return;
}
However, not so many people will know that in grep, there is a similar option, “-m1”
$ grep -m1 $pattern $log_file
Case insensitive searches can potentially be turned into faster case sensitive ones
This does not affect the example above because all our strings are invariant under case transformations but suppose we wanted to match a username jord0001@ox.ac.uk) for example. We know that the username might have authenticated with a mix of cases, an example being (JOrd0001@OX.AC.UK). We could write a case insensitive regular expression
grep -i 'jord0001@ox\.ac\.uk' $log_file
However this will kill performance and this has bitten us in the past. On our CentOS 5 servers at least , there appears to be a bug in which a case insensitive search runs 100 times slower than a case sensitive one. Unicode is the ultimate cause and if you know that the username is ASCII (which we do), then a cute workaround is to perform a case sensitive search such as:
grep '[jJ][oO][rR][dD]0001@[oO][xX]\.[aA][cC]\.[uU][kK]' $log_file
This sure isn’t pretty, but it works and allows us to search our logs in reasonable time. It should be faster than the alternative of changing the locale as advised in the linked bug ticket. In a similar fashion, perl’s /i performs case folding before matching, which can be given a speed boost using the technique above.
Further reading
- Programming perl – This is the book to read if you want to understand perl at any significant level. The main gripe people had was that it was out of date, but there is a fourth edition that was released in 2012 which contains the latest best practices. It also contains a section on optimizing perl
- Mastering regular expressions – If you’re comfortable with your regular expression capabilities, I would probably guess you haven’t read this book. It will open your eyes to the nuances and pitfalls when writing them. It’s well worth a read and isn’t as dry as the subject is presented in other books that I’ve read.
- natlog – A program that has similar aims as what we required. This is written in C++ but the principle is the same. The main drawback (unless I am misunderstanding the documentation) is that it logs the connection on termination, not instantiation. This means that the log lines will be written after the event, which for a (hypothetical) connection that never ended, it would never be logged at all and since our searching is for connection start rather than end, this program is not very useful for us.
Coming up
That concludes this post on logging. The next post will be a demonstration of what we monitor.


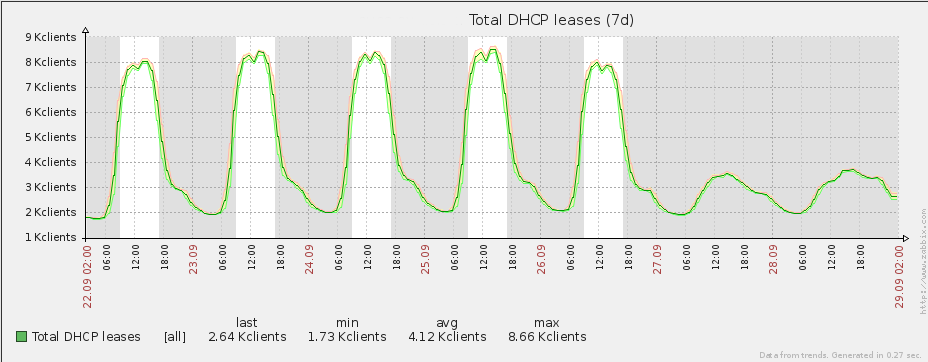
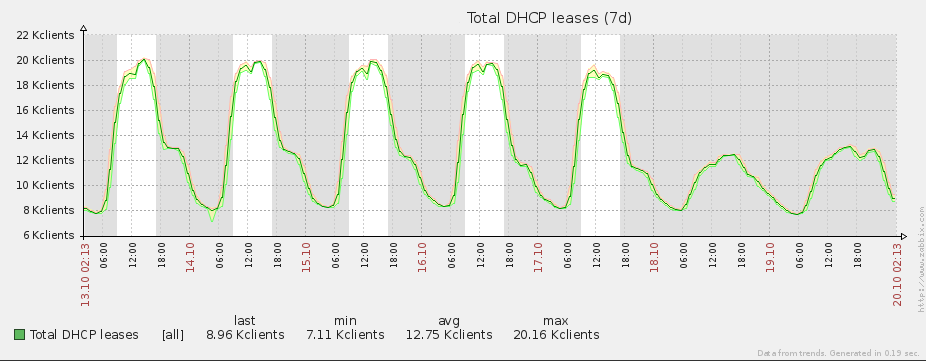
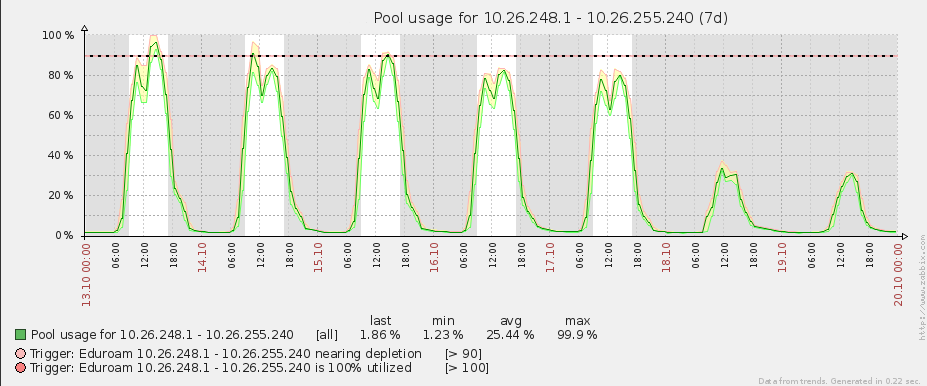
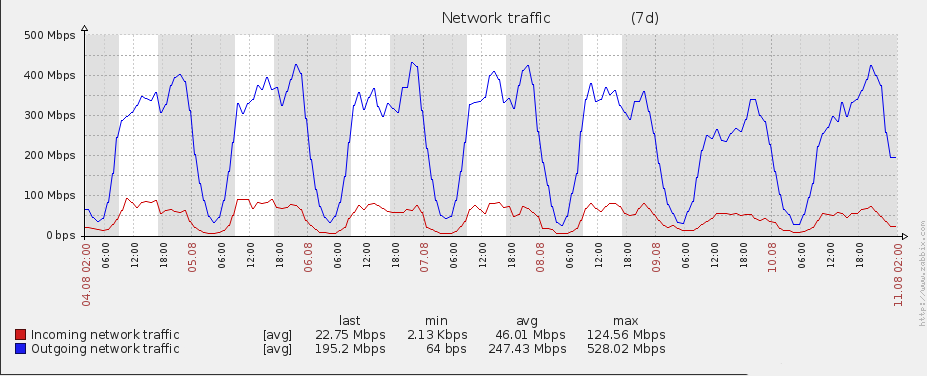
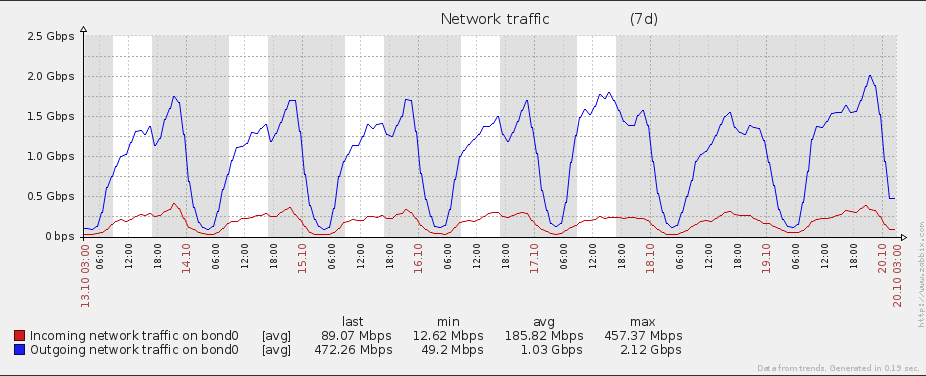
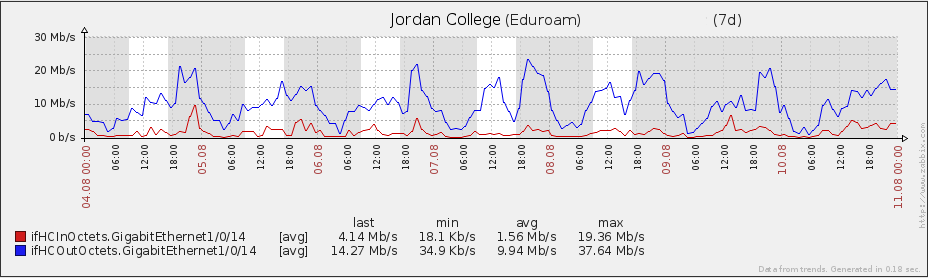
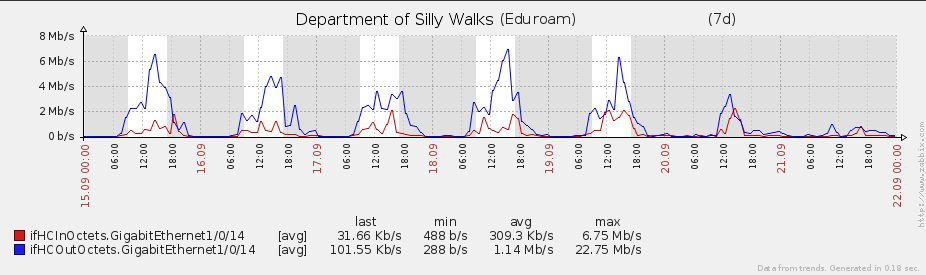
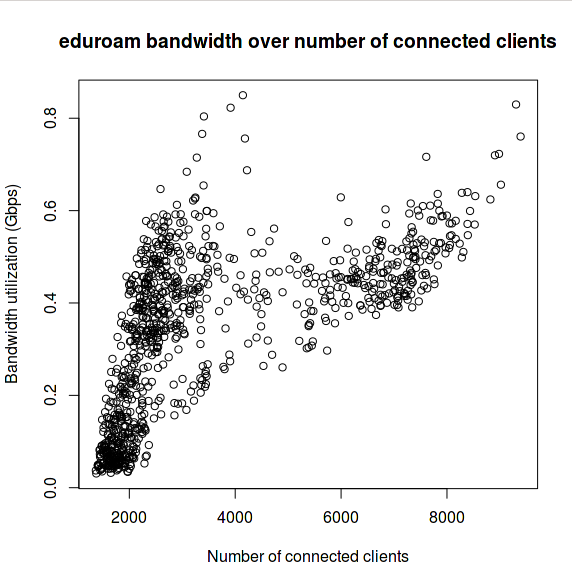
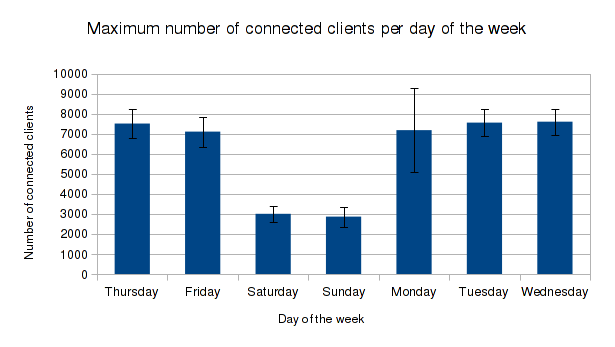
 When upgrading the eduroam infrastructure, there was one goal in mind: increase the bandwidth over the previous one. The old infrastructure made use of a Linux box to perform NAT, netflow and firewalling duties. This can all be achieved with dedicated hardware, but the cost was prohibitive and since the previous eduroam solution involved Linux in the centre, the feeling was that replacing like-for-like would yield results faster than would more exotic changes to infrastructure.
When upgrading the eduroam infrastructure, there was one goal in mind: increase the bandwidth over the previous one. The old infrastructure made use of a Linux box to perform NAT, netflow and firewalling duties. This can all be achieved with dedicated hardware, but the cost was prohibitive and since the previous eduroam solution involved Linux in the centre, the feeling was that replacing like-for-like would yield results faster than would more exotic changes to infrastructure.
 This may be controversial. I will say now that we here in the Networks team use and love Linux Debian. However, there is a very vocal support for BSD firewalls and routers, and these supporters may have a point. It’s hard to say it tactfully so I’ll just say it bluntly: iptables’s syntax can be a little, ahem, bizarre. The only reason that anyone would say otherwise is because he or she is so used to it that writing new rules is second nature.
This may be controversial. I will say now that we here in the Networks team use and love Linux Debian. However, there is a very vocal support for BSD firewalls and routers, and these supporters may have a point. It’s hard to say it tactfully so I’ll just say it bluntly: iptables’s syntax can be a little, ahem, bizarre. The only reason that anyone would say otherwise is because he or she is so used to it that writing new rules is second nature.